

Apache Spark 使用 Alluxio
![]()

![]()
该指南描述了如何配置 Apache Spark 来访问 Alluxio。
概览
Spark 1.1 或更高版本的 Spark 应用程序可以通过其与 HDFS 兼容的接口直接访问 Alluxio 集群。 使用 Alluxio 作为数据访问层,Spark 应用程序可以透明地访问许多不同类型的持久化存储服务(例如,AWS S3 bucket、Azure Object Store buckets、远程部署的 HDFS 等)的数据,也可以透明地访问同一类型持久化存储服务不同实例中的数据。 为了加快 I/O 性能,用户可以主动获取数据到 Alluxio 中或将数据透明地缓存到 Alluxio 中。 这种做法尤其是在 Spark 部署位置与数据相距较远时特别有效。 此外,通过将计算和物理存储解耦,Alluxio 能够有助于简化系统架构。 当底层持久化存储中真实数据的路径对 Spark 隐藏时,对底层存储的更改可以独立于应用程序逻辑;同时,Alluxio 作为邻近计算的缓存,仍然可以给计算框架提供类似 Spark 数据本地性的特性。
前期准备
- 安装 Java 8 Update 60 或更高版本(8u60+)的 64 位 Java。
- 已经安装并运行 Alluxio。
本指南假设底层持久存储为本地部署的 HDFS。例如,
${ALLUXIO_HOME}/conf/alluxio-site.properties中包含alluxio.master.mount.table.root.ufs=hdfs://localhost:9000/alluxio/这一行。 请注意,除了 HDFS,Alluxio 还支持许多其他底层存储系统。 从任意数量的这些系统中访问数据与本指南的重点是垂直的, 统一命名空间文档介绍了相关内容。 - 确保 Alluxio 客户端 jar 包是可用的。
在从 Alluxio 下载页面下载的压缩包的
/<PATH_TO_ALLUXIO>/client/alluxio-2.8.1-client.jar中,可以找到 Alluxio 客户端 jar 包。 高级用户也可以从源代码编译该客户端 jar 包,可以参考从源代码构建 Alluxio 的步骤。
基础设置
将 Alluxio客户端 jar 包分发在运行 Spark driver 或 executor 的节点上。具体地说,将客户端 jar 包放在每个节点上的同一本地路径(例如/<PATH_TO_ALLUXIO>/client/alluxio-2.8.1-client.jar)。
将 Alluxio 客户端 jar 包添加到 Spark driver 和 executor 的 classpath 中,以便 Spark 应用程序能够使用客户端 jar 包在 Alluxio 中读取和写入文件。具体来说,在运行 Spark 的每个节点上,将以下几行添加到spark/conf/spark-defaults.conf中。
spark.driver.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.8.1-client.jar
spark.executor.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.8.1-client.jar
示例:使用 Alluxio 作为输入和输出
本节介绍如何使用 Alluxio 作为 Spark 应用程序的输入和输出。
访问仅在Alluxio中的数据
将本地数据复制到 Alluxio 文件系统中。
假设你在 Alluxio 项目目录中,将LICENSE文件放入 Alluxio,运行:
$ ./bin/alluxio fs copyFromLocal LICENSE /Input
假设 Alluxio Master 运行在localhost上,在spark-shell中运行如下命令:
> val s = sc.textFile("alluxio://localhost:19998/Input")
> val double = s.map(line => line + line)
> double.saveAsTextFile("alluxio://localhost:19998/Output")
打开浏览器,查看 http://localhost:19999/browse。
应该存在一个输出目录/Output,其中包含了输入文件Input的双倍内容。
访问底层存储中的数据
给出准确路径后,Alluxio 支持透明地从底层存储系统中获取数据。 在本节中,使用 HDFS 作为分布式存储系统的示例。
将Input_HDFS文件放入到 HDFS 中:
$ hdfs dfs -put -f ${ALLUXIO_HOME}/LICENSE hdfs://localhost:9000/alluxio/Input_HDFS
请注意,Alluxio 并不知道该文件。你可以通过访问 Web UI 来验证这一点。
假设 Alluxio Master 运行在localhost上,在spark-shell中运行如下命令:
> val s = sc.textFile("alluxio://localhost:19998/Input_HDFS")
> val double = s.map(line => line + line)
> double.saveAsTextFile("alluxio://localhost:19998/Output_HDFS")
打开浏览器,查看 http://localhost:19999/browse。
应该存在一个输出目录Output_HDFS,其中包含了输入文件Input_HDFS的双倍内容。
同时,现在输入文件Input_HDFS会被 100% 地加载到 Alluxio 的文件系统空间。
高级设置
为所有 Spark 作业自定义 Alluxio 用户属性
让我们以设置 Spark 与 HA 模式的 Alluxio 服务进行通信为例。
如果你运行多个 Alluxio master,其中 Zookeeper 服务运行在zkHost1:2181、zkHost2:2181和zkHost3:2181,
将以下几行添加到${SPARK_HOME}/conf/spark-defaults.conf中:
spark.driver.extraJavaOptions -Dalluxio.zookeeper.address=zkHost1:2181,zkHost2:2181,zkHost3:2181 -Dalluxio.zookeeper.enabled=true
spark.executor.extraJavaOptions -Dalluxio.zookeeper.address=zkHost1:2181,zkHost2:2181,zkHost3:2181 -Dalluxio.zookeeper.enabled=true
或者,你也可以在 Hadoop 配置文件${SPARK_HOME}/conf/core-site.xml中添加如下属性:
<configuration>
<property>
<name>alluxio.zookeeper.enabled</name>
<value>true</value>
</property>
<property>
<name>alluxio.zookeeper.address</name>
<value>zkHost1:2181,zkHost2:2181,zkHost3:2181</value>
</property>
</configuration>
在 Alluxio 1.8 (不包含 1.8)后,用户可以在 Alluxio URI 中编码 Zookeeper 服务地址(见详细说明#ha-configuration-parameters)。 这样,就不需要为 Spark 配置额外设置。
为单个 Spark 作业自定义 Alluxio 用户属性
Spark 用户可以将 JVM 系统设置传递给 Spark 任务,通过将"-Dproperty=value"添加到spark.executor.extraJavaOptions来设置 Spark executor,将"-Dproperty=value"添加到spark.driver.extraJavaOptions中来设置 spark driver。例如,要在写入 Alluxio 时提交CACHE_THROUGH写模式的 Spark 任务,请执行以下操作:
$ spark-submit \
--conf 'spark.driver.extraJavaOptions=-Dalluxio.user.file.writetype.default=CACHE_THROUGH' \
--conf 'spark.executor.extraJavaOptions=-Dalluxio.user.file.writetype.default=CACHE_THROUGH' \
...
如果需要自定义 Spark 任务中的 Alluxio 客户端侧属性,请参见如何配置 Spark 任务。
请注意,在客户端模式中,你需要设置--driver-java-options "-Dalluxio.user.file.writetype.default=CACHE_THROUGH",而不是--conf spark.driver.extraJavaOptions=-Dalluxio.user.file.writetype.default=CACHE_THROUGH(见解释)。
高级用法
从 HA 模式的 Alluxio 中访问数据
如果 Spark 已经根据 HA 模式的 Alluxio 中的步骤进行了设置,
你就可以使用”alluxio://“方案编写 URI,而无需在权限中指定 Alluxio master。
这是因为在 HA 模式下,Alluxio 主 master 的地址将由配置的 ZooKeeper 服务提供 ,
而不是由从 URI 推断的用户指定主机名提供。
> val s = sc.textFile("alluxio:///Input")
> val double = s.map(line => line + line)
> double.saveAsTextFile("alluxio:///Output")
或者,如果在 Spark 配置中没有设置 Alluxio HA 的 Zookeeper 地址,则可以在 URI 中以”zk@zkHost1:2181;zkHost2:2181;zkHost3:2181“的格式指定 Zookeeper 地址:
> val s = sc.textFile("alluxio://zk@zkHost1:2181;zkHost2:2181;zkHost3:2181/Input")
> val double = s.map(line => line + line)
> double.saveAsTextFile("alluxio://zk@zkHost1:2181;zkHost2:2181;zkHost3:2181/Output")
请注意,你必须使用分号而不是逗号来分隔不同的 ZooKeeper 地址,以便在 Spark 中引用 HA 模式的 Alluxio 的 URI;否则,Spark 会认为该 URI 无效。请参阅连接高可用 Alluxio 的 HDFS API。
缓存 RDD 到 Alluxio 中
存储 RDD 到 Alluxio 内存中就是将 RDD 作为文件保存到 Alluxio 中。 在 Alluxio 中将 RDD 保存为文件的两种常见方法是
saveAsTextFile:将 RDD 作为文本文件写入,其中每个元素都是文件中的一行,saveAsObjectFile:通过对每个元素使用 Java 序列化,将 RDD 写到一个文件中。
通过分别使用sc.textFile或sc.objectFile,可以从内存中再次读取保存在 Alluxio 中的 RDD。
// as text file
> rdd.saveAsTextFile("alluxio://localhost:19998/rdd1")
> rdd = sc.textFile("alluxio://localhost:19998/rdd1")
// as object file
> rdd.saveAsObjectFile("alluxio://localhost:19998/rdd2")
> rdd = sc.objectFile("alluxio://localhost:19998/rdd2")
见博客文章“通过 Alluxio 高效使用 Spark RDD”。
缓存 Dataframe 到 Alluxio 中
存储 Spark DataFrame 到 Alluxio 内存中就是将 DataFrame 作为文件保存到 Alluxio 中。
DataFrame 通常用df.write.parquet()作为 parquet 文件写入。
将 parquet 写入 Alluxio 后,可以使用sqlContext.read.parquet()从内存中读取。
> df.write.parquet("alluxio://localhost:19998/data.parquet")
> df = sqlContext.read.parquet("alluxio://localhost:19998/data.parquet")
见博客文章”通过 Alluxio 高效使用 Spark DataFrame”.
故障排除指南
日志配置
如果是为了调试,你可以配置 Spark 应用程序的日志。 Spark 文档解释了 如何配置 Spark 应用程序的日志。
如果你用的是 YARN,则有单独一节来解释 如何配置 YARN 下的 Spark 应用程序的日志。
Spark 任务的数据本地性级别错误
如果 Spark 任务的本地性级别是ANY(本应该是NODE_LOCAL),这可能是因为 Alluxio 和 Spark 使用不同的网络地址表示,可能其中一个使用主机名,而另一个使用 IP 地址。更多详情请参考 JIRA ticket SPARK-10149(这里可以找到 Spark 社区的解决方案)。
注意:Alluxio worker 使用主机名来表示网络地址,以便与 HDFS 保持一致。 有一个变通方法,可以在启动 Spark 时实现数据本地性。用户可以使用 Spark 中提供的以下脚本显式指定主机名。在每个从节点中以 slave-hostname 启动 Spark worker:
$ ${SPARK_HOME}/sbin/start-slave.sh -h <slave-hostname> <spark master uri>
例如:
$ ${SPARK_HOME}/sbin/start-slave.sh -h simple30 spark://simple27:7077
你也可以在$SPARK_HOME/conf/spark-env.sh中设置SPARK_LOCAL_HOSTNAME来达到此目的。例如:
SPARK_LOCAL_HOSTNAME=simple30
无论采用哪种方式,Spark Worker 地址都将变为主机名,并且本地性级别将变为NODE_LOCAL,如下面的 Spark WebUI 所示。

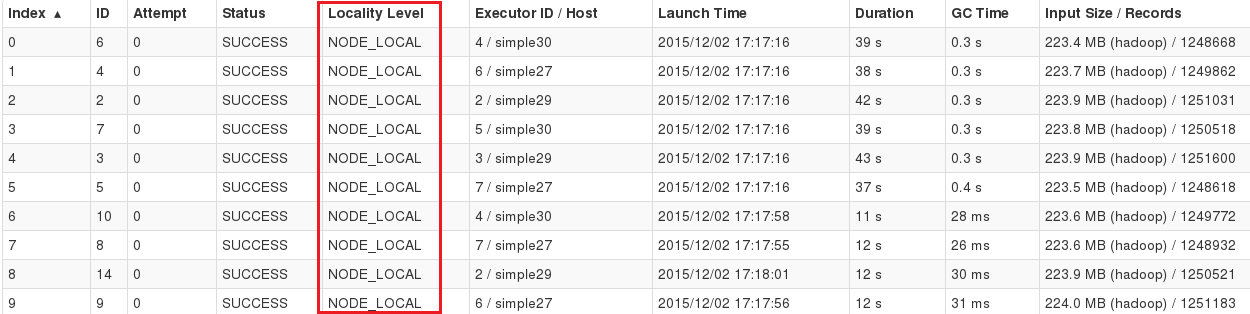
YARN 上的 Spark 作业的数据本地性
为了最大化实现 Spark 作业的本地性,你应该尽可能多地使用 executor,我们希望每个节点至少有一个 executor。 和部署 Alluxio 的所有方法一样,所有计算节点上也应该有一个 Alluxio worker。
当 Spark 作业在 YARN 上运行时,Spark 会在不考虑数据本地性的情况下启动其 executor。
之后 Spark 在决定怎样为其 executor 分配任务时会正确地考虑数据的本地性。
例如,如果host1包含blockA,并且使用blockA的作业已经在 YARN 集群上以--num-executors=1的方式启动了,Spark 可能会将唯一的 executor 放置在host2上,本地性会较差。
但是,如果以--num-executors=2的方式启动,并且 executor 在host1和host2上启动,Spark 会足够智能地将作业优先放置在host1上。
Class alluxio.hadoop.FileSystem not found与 SparkSQL 和 Hive MetaStore 有关的问题
为了用 Alluxio 客户端运行spark-shell,Alluxio 客户端 jar 包必须如之前描述的那样,被添加到 Spark driver 和 Spark executor 的 classpath 中。
然而有的时候,SparkSQL 在保存表到 Hive MetaStore(位于 Alluxio 中)中时可能会失败,出现类似于下面的错误信息:
org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:java.lang.RuntimeException: java.lang.ClassNotFoundException: Class alluxio.hadoop.FileSystem not found)
推荐的解决方案是配置spark.sql.hive.metastore.sharedPrefixes。
在 Spark 1.4.0 和之后的版本中,Spark 为了访问 Hive MetaStore 使用了独立的类加载器来加载 java 类。
然而,这个独立的类加载器忽视了特定的包,并且让主类加载器去加载”共享”类(Hadoop 的 HDFS 客户端就是一种”共享”类)。
Alluxio 客户端也应该由主类加载器加载,你可以将alluxio包加到配置参数spark.sql.hive.metastore.sharedPrefixes中,以通知 Spark 用主类加载器加载 Alluxio。例如,该参数可以在spark/conf/spark-defaults.conf中这样设置:
spark.sql.hive.metastore.sharedPrefixes=com.mysql.jdbc,org.postgresql,com.microsoft.sqlserver,oracle.jdbc,alluxio
java.io.IOException: No FileSystem for scheme: alluxio 与在 YARN 上运行 Spark 有关的问题
如果你在 YARN 上使用基于 Alluxio 的 Spark 并遇到异常java.io.IOException: No FileSystem for scheme: alluxio,
请将以下内容添加到${SPARK_HOME}/conf/core-site.xml:
<configuration>
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
</configuration>