

在Alluxio上运行深度学习框架
![]()

![]()
- 内容列表
随着数据集规模的增大以及计算能力的增强,深度学习已成为人工智能的一项流行技术。能够获取的数据量的增多以及训练更大神经网络的处理能力的增强使得深度 学习模型在多个领域内的性能正在获得持续的提升。深度学习的兴起促进了人工智能的最新发展,但也暴露出了其在访问数据和存储系统的一些问题。在本文中,我 们将进一步描述深度学习的工作负载所带来的存储挑战,并展示Alluxio如何帮助解决这些挑战。
深度学习的数据挑战
由于能够获取到海量有用的数据,深度学习已成为机器学习的热门,因为通常更多的数据会带来更好的性能。然而,并不是所有存储系统上的训练数据都可直接用于 深度学习框架(Tensorflow,Caffe,torch)。例如,深度学习框架已经和一些已有的存储系统集成,但是并不是所有的存储系统集成都是可行的。因此,深度学 习框架可能无法获取某个存储系统上的数据子集并进行训练,导致训练效率和效果的降低。
此外,随着分布式存储系统(HDFS,ceph)和云存储(AWS S3,Azure Blob Store,Google云存储)的流行,用户有了多种存储可供选择。然而,相较于简 单地使用本地机器上的文件系统,从业者需要以不熟悉的方式与这些分布式和远程存储系统进行交互。正确配置每个存储系统和使用新的工具可能很困难,这使得使 用深度学习框架访问不同存储系统获取数据变得困难。
最后,计算资源与存储资源分离的趋势导致远程存储系统的使用变得更为必要。这在云计算中很常见,使用远程存储系统可以实现资源按需分配,从而提高利 用率,增加弹性和降低成本。但是,当深度学习需要使用远程存储系统的数据时,它必须通过网络获取,这可能会增加深度学习的训练时间。额外的网络IO会 提高成本并增加处理数据的时间。
Alluxio如何帮助解决深度学习的存储问题
Alluxio可以帮助解决深度学习的数据访问问题。Alluxio最简单的形式是一个虚拟文件系统,它透明地连接到现有的存储系统,并将它们作为一个单一 的系统呈现给用户。使用Alluxio的统一命名空间,可以将许多存储系统挂载到Alluxio中,包括S3, Azure和GCS等云存储系统。由于Alluxio已经与存储系统集成了,因此深度学习框架只需与Alluxio进行交互即可访问所有存储中的数据。这为从任何数据源获得 数据并进行训练打开了大门,从而可以提高深度学习学得的模型的性能。
Alluxio还包括一个可以提供便利和人性化的使用体验的FUSE界面。使用Alluxio POSIX API,可以将Alluxio实 例挂载到本地文件系统,因此与Alluxio的交互就跟与本地文件或者目录的交互一样简单。这使用户能够继续使用熟悉的工具和范例与其数据进行交互。Alluxio 可以连接到多个不同的存储系统,这意味着来自任何存储的任何数据看起来都跟本地文件或目录一样。
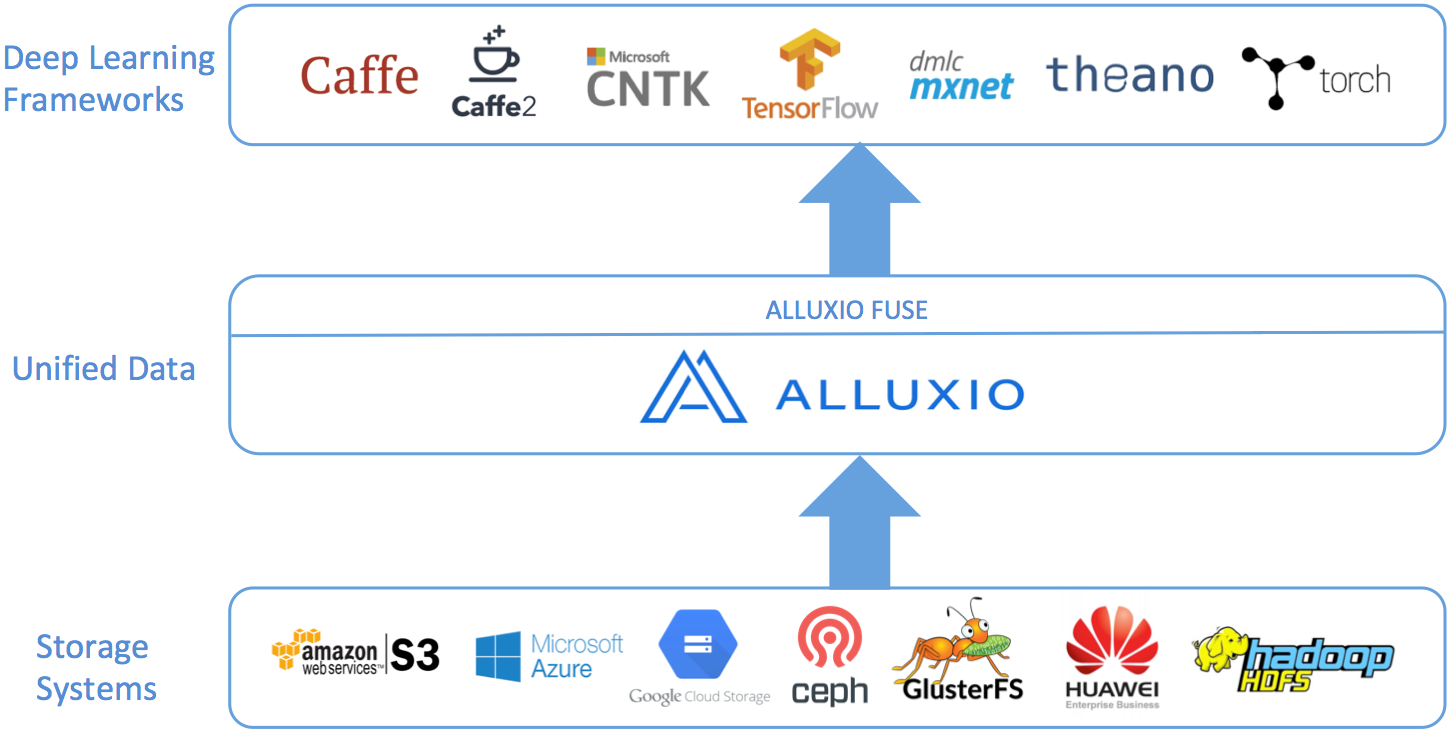
最后,Alluxio还提供常用数据的本地缓存。当数据远离计算时,这非常有用,例如存储环境中的计算分离。由于Alluxio可以 在本地缓存数据,所以不需要通过网络IO来访问数据,从而使得深度学习训练的成本会更低,并且花费的时间会更少。
设置 Alluxio FUSE
在本节中,我们将按照FUSE部分中的说明设置FUSE,访问S3中ImageNet的训练数据,并允许深度学习框架 通过FUSE访问数据。
首先在Alluxio的根目录下创建一个文件夹。
$ ./bin/alluxio fs mkdir /training-data
然后我们可以把存储在S3桶中的ImageNet数据挂载到路径 /training-data/imagenet上。假定数据在s3中的路径是 s3://alluxio-tensorflow-imagenet/。
$ ./bin/alluxio fs mount /training-data/imagenet/ \
s3://alluxio-tensorflow-imagenet/ \
--option s3a.accessKeyID=<ACCESS_KEY_ID> \
--option s3a.secretKey=<SECRET_KEY>
请注意,此命令需要传递存储桶的S3证书。这些证书与挂载点相关联,这样之后的访问就不需要证书了。
之后,我们会启动Alluxio-FUSE进程。首先,我们创建一个名为 /mnt/fuse 的目录,把它的所有者改成当前的使用者(本文档中是ec2-user),并且设置
权限为可读写。
$ sudo mkdir -p /mnt/fuse
$ sudo chown ec2-user:ec2-user /mnt/fuse
$ chmod 664 /mnt/fuse
然后我们运行 Alluxio-FUSE shell 来将Alluxio目录下的 training-data 挂载到本地目录 /mnt/fuse 下面。
$ ./integration/fuse/bin/alluxio-fuse mount /mnt/fuse /training-data
现在,你可以访问挂载目录并浏览其中的数据了,你应该能看到存储在云中的数据。
$ cd /mnt/fuse
$ ls
该文件夹已准备好供深度学习框架使用,深度学习框架将把Alluxio存储视为本地文件夹。我们将在下一节中使用此文件夹进行Tensorflow训练。
使用Tensorflow访问Alluxio FUSE
在本文档中我们以深度学习框架Tensorflow为例,展示Alluxio如何帮助框架进行数据访问和管理。要通过Alluxio(Alluxio FUSE)访问S3中的训练数据,
我们可以简单地将/mnt/fuse/imagenet路径传递给基准脚本的参数data_dirtf_cnn_benchmarsk.py。
一旦挂载完底层存储器,即可立即通过Alluxio访问各种底层存储器中的数据。并且各种数据可以透明的放入benchmark中而无需对Tensorflow或benchmark脚 本进行任何修改。这大大简化了应用程序开发,否则需要整合并且配置每个特定的存储系统。
除了提供统一的访问接口,Alluxio也可以带来性能上的好处。 beanchmark通过输入的训练图像(单位为 图像数/秒)评价训练模型的吞吐量。 训练过程涉及三个阶段,每个阶段使用不同的资源:
- 数据读取(I/O):从源中选择并且读取图像。
- 图像处理(CPU):把图像记录解码成图像,预处理,然后组织成mini-batches。
- 模型训练(GPU):在多个卷积层上计算并且更新参数。
通过将Alluxio worker与深度学习框架搭配在一起,Alluxio将远程数据缓存到本地以供将来访问,从而提供数据本地性。没有Alluxio,缓慢的远程存储可能 会导致I/O瓶颈,并使宝贵的GPU资源得不到利用。例如,在benchmark模型中,我们发现AlexNet架构相对简单,因此当存储变得更慢时,更容易出现I/O性能瓶 颈。在一台EC2 p2.8xlarge机器上运行Alluxio可以带来近2倍的性能提升。