

架构
![]()

![]()
Architecture Overview
Alluxio作为大数据和机器学习生态系统中的新增数据访问层,可位于任何持久化存储系统(如Amazon S3、Microsoft Azure 对象存储、Apache HDFS或OpenStack Swift)和计算框架(如Apache Spark、Presto或Hadoop MapReduce)之间,但是Alluxio本身并非持久化存储系统。使用Alluxio作为数据访问层可带来诸多优势:
-
对于用户应用和计算框架而言,Alluxio提供的快速存储可以让任务(无论是否在同一计算引擎上运行)进行数据共享,并且在同时将数据缓存在本地计算集群。因此,当数据在本地时,Alluxio可以提供内存级别的数据访问速度;当数据在Alluxio中时,Alluxio将提供计算集群网络带宽级别的数据访问速度。数据只需在第一次被访问时从底层存储系统中读取一次即可。因此,即使底层存储的访问速度较慢,也可以通过Alluxio显著加速数据访问。为了获得最佳性能,建议将 Alluxio与集群的计算框架部署在一起。
-
就底层存储系统而言,Alluxio将大数据应用和不同的存储系统连接起来,因此扩充了能够利用数据的可用工作负载集。由于Alluxio和底层存储系统的集成对于应用程序是透明的,因此任何底层存储都可以通过Alluxio支持数据访问的应用和框架。此外,当同时挂载多个底层存储系统时,Alluxio可以作为任意数量的不同数据源的统一层。
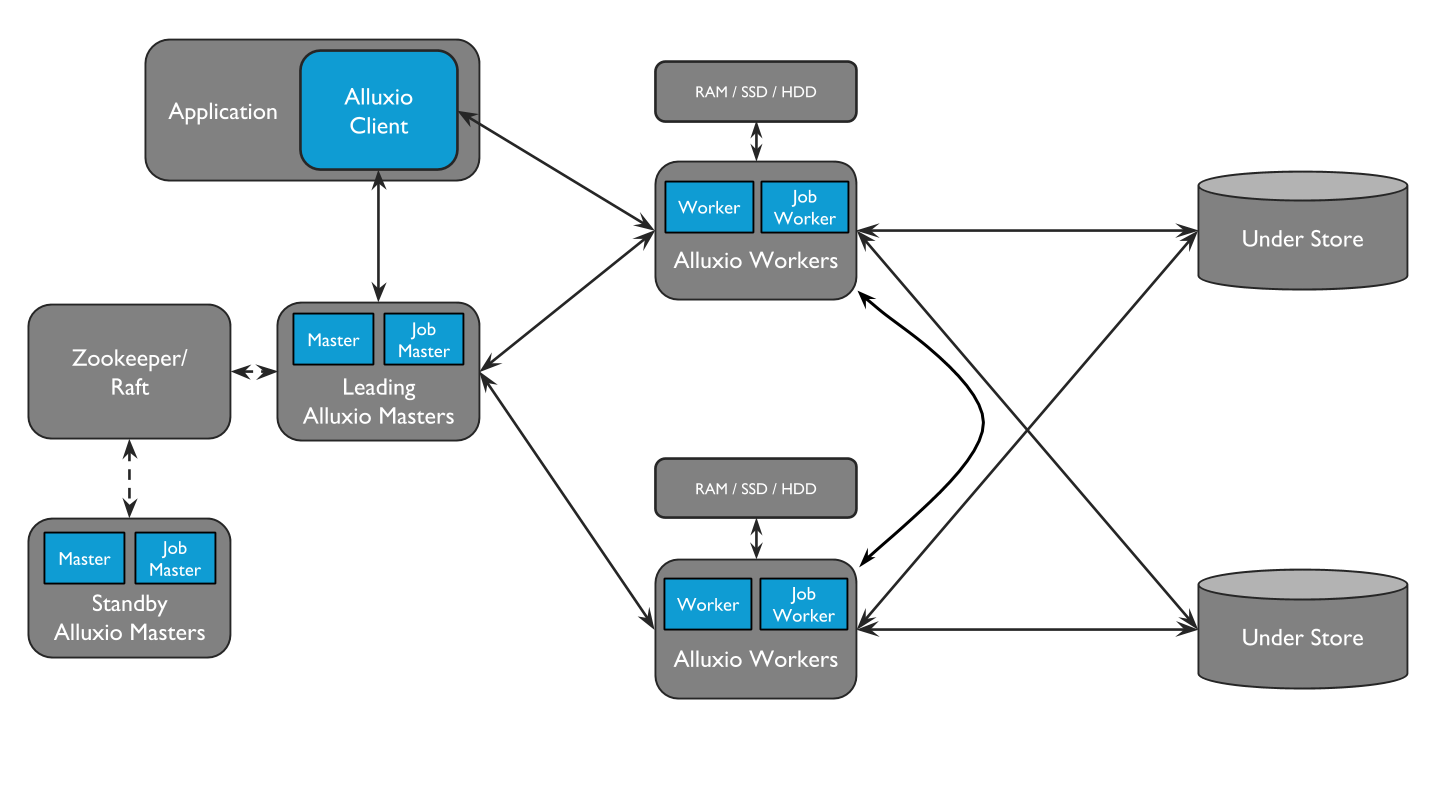
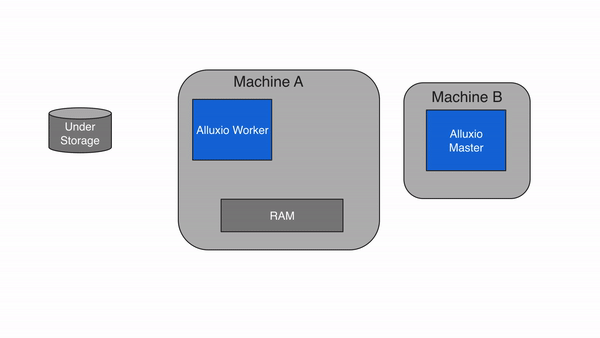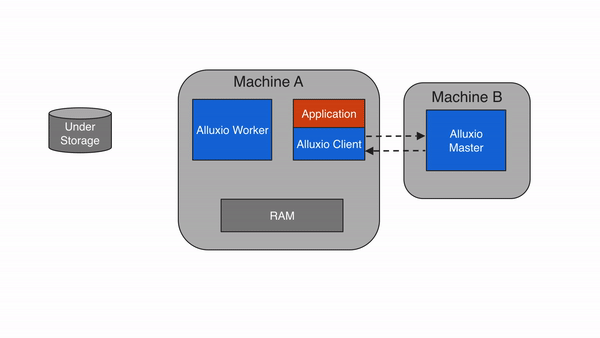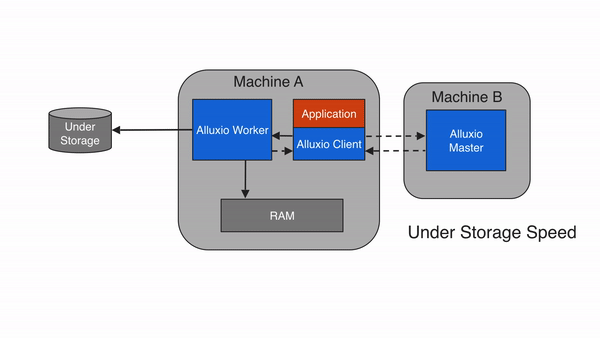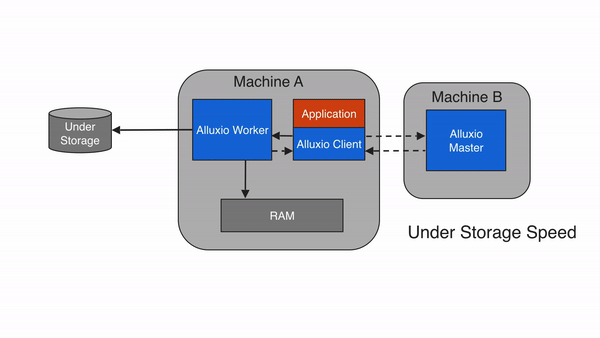
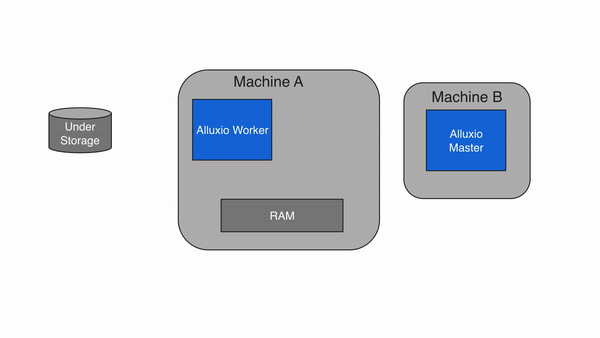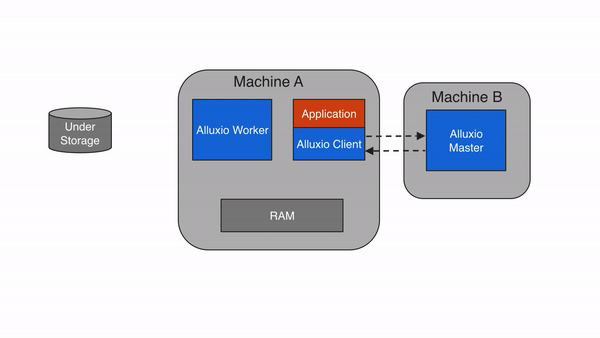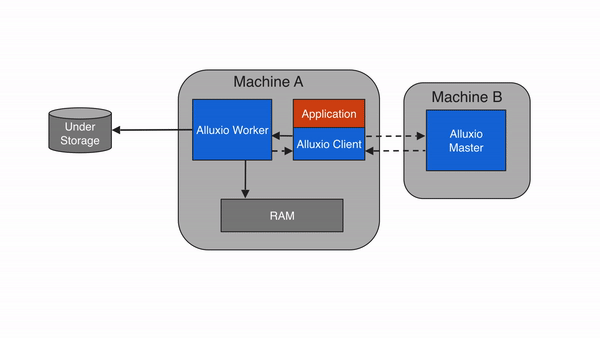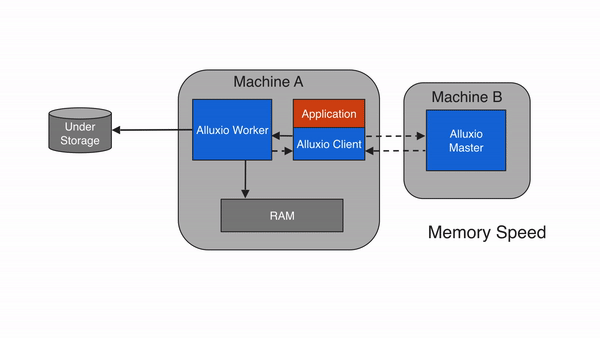
Alluxio包含三种组件:master、worker和client。一个集群通常包含一个leading master,多个standby master,一个primary job master、多个standby job master,多个worker和多个job workers 。master进程和worker进程通常由系统管理员维护和管理,构成了Alluxio server(服务端)。而应用程序(如Spark或MapReduce作业、Alluxio命令行或FUSE层)通过client(客户端)与Alluxio server进行交互。
Alluxio Job Masters和Job Worker可以归为一个单独的功能,称为Job Service。Alluxio Job Service是一个轻量级的任务调度框架,负责将许多不同类型的操作分配给Job Worker。这些任务包括:
- 将数据从UFS(under file system)加载到Alluxio
- 将数据持久化到UFS
- 在Alluxio中复制文件
- 在UFS间或Alluxio节点间移动或拷贝数据
Job service的设计使得所有与Job相关的进程不一定需要与其他Alluxio集群位于同一位置。但是,为了使得RPC和数据传输延迟较低,我们还是建议将job worker与对应的Alluxio worker并置。
Masters
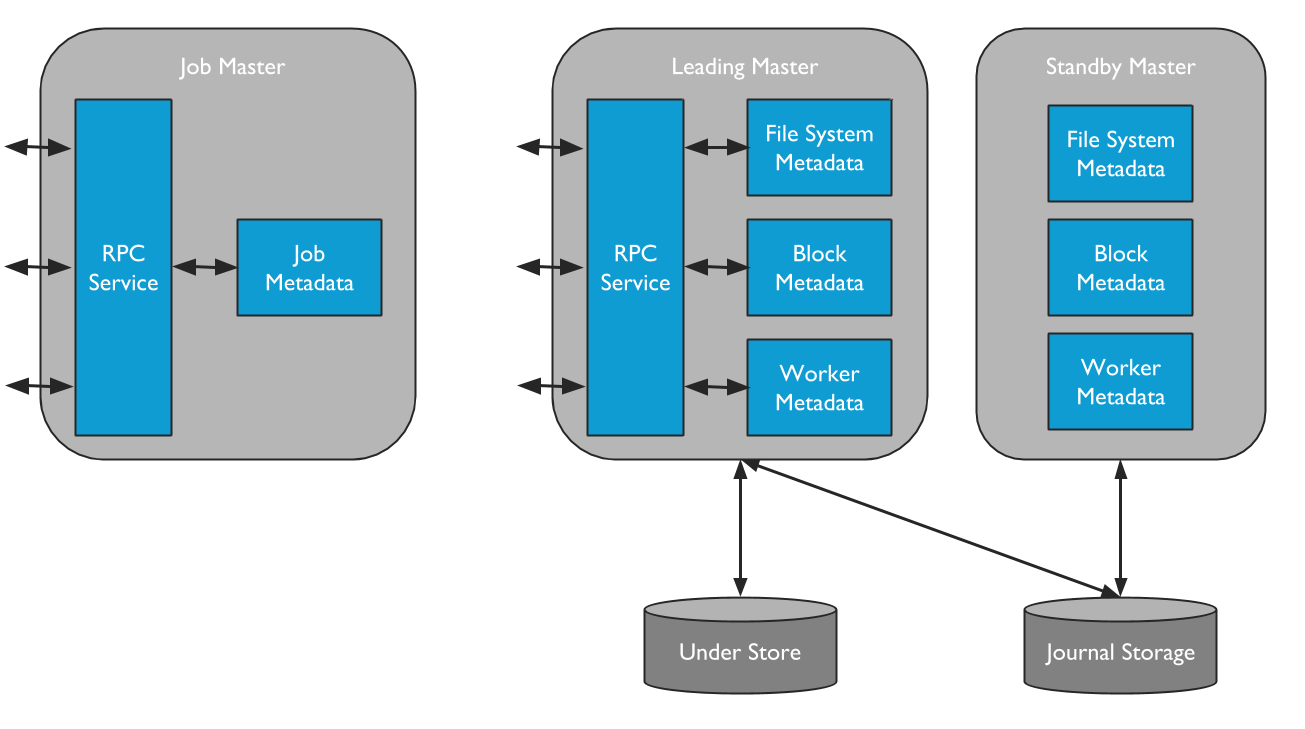
Alluxio包含两种不同类型的master进程。一种是Alluxio Master,Alluxio Master服务所有用户请求并记录文件系统元数据修改情况。另一种是Alluxio Job Master,这是一种用来调度将在Alluxio Job Workers上执行的各种文件系统操作的轻量级调度程序。
为了提供容错能力,可以以一个leading master和多个备用master的方式来部署Alluxio Master。当leading master宕机时,某个standby master会被选举成为新的leading master。
Leading Master
Alluxio集群中只有一个leading master,负责管理整个集群的全局元数据,包括文件系统元数据(如索引节点树)、数据块(block)元数据(如block位置)以及worker容量元数据(空闲和已用空间)。leading master只会查询底层存储中的元数据。应用数据永远不会通过master来路由传输。Alluxio client通过与leading master交互来读取或修改元数据。此外,所有worker都会定期向leading master发送心跳信息,从而维持其在集群中的工作状态。leading master通常不会主动发起与其他组件的通信,只会被动响应通过RPC服务发来的请求。此外,leading master还负责将日志写入分布式持久化存储,保证集群重启后能够恢复master状态信息。这组记录被称为日志(Journal)。
Standby Masters
standby master在不同的服务器上启动,确保在高可用(HA)模式下运行Alluxio时能提供容错。standby master读取leading master的日志,从而保证其master状态副本是最新的。standby master还编写日志检查点, 以便将来能更快地恢复到最新状态。但是,standby master不处理来自其他Alluxio组件的任何请求。当leading master出现故障后,standby master会重新选举新的leading master。
Secondary master(用于UFS 日志)
当使用UFS日志运行非HA模式的单个Alluxio master时,可以在与leading master相同的服务器上启动secondary master来编写日志检查点。请注意,secondary master并非用于提供高可用,而是为了减轻leading master的负载,使其能够快速恢复到最新状态。与standby master不同的是,secondary master永远无法升级为leading master。
Job Masters
Alluxio Job Master是负责在Alluxio中异步调度大量较为重量级文件系统操作的独立进程。通过将执行这些操作的需求从在同一进程中的leading Alluxio Master上独立出去,Leading Alluxio Master会消耗更少的资源,并且能够在更短的时间内服务更多的client。此外,这也为将来增加更复杂的操作提供了可扩展的框架。
Alluxio Job Master接受执行上述操作的请求,并在将要具体执行操作的(作为Alluxio 文件系统client的)Alluxio Job Workers间进行任务调度。下一节将对job worker作更多的介绍。
Workers
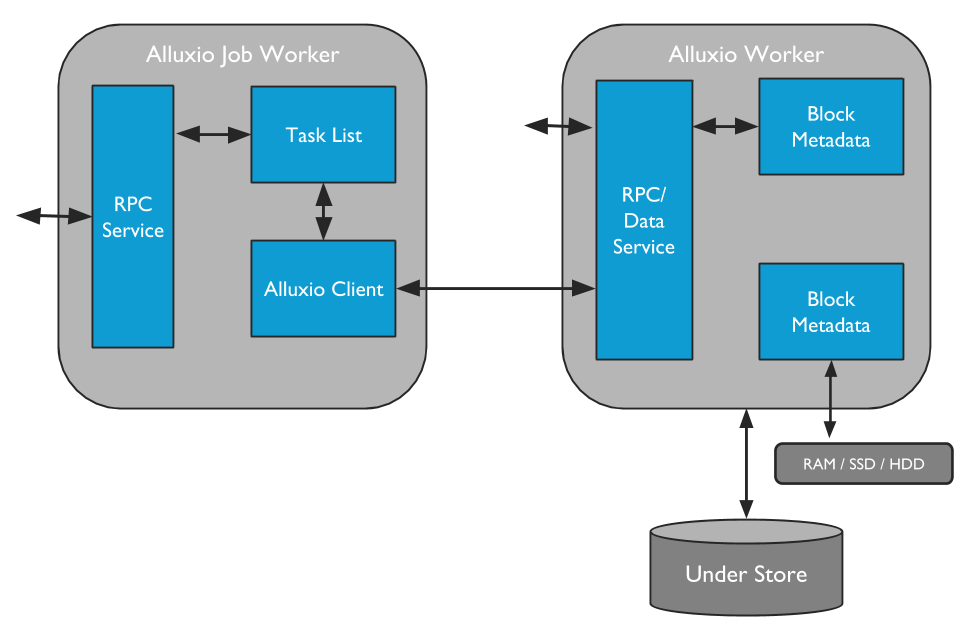
Alluxio Workers
Alluxio worker负责管理分配给Alluxio的用户可配置本地资源(RAMDisk、SSD、HDD 等)。Alluxio worker以block为单位存储数据,并通过在其本地资源中读取或创建新的block来服务client读取或写入数据的请求。worker只负责管理block, 从文件到block的实际映射都由master管理。
Worker在底层存储上执行数据操作, 由此带来两大重要的益处:
- 从底层存储读取的数据可以存储在worker中,并可以立即提供给其他client使用。
- client可以是轻量级的,不依赖于底层存储连接器。
由于RAM通常提供的存储容量有限,因此在Alluxio worker空间已满的情况下,需要释放worker中的block。Worker可通过配置释放策略(eviction policies)来决定在Alluxio空间中将保留哪些数据。有关此主题的更多介绍,请查看分层存储文档。
Alluxio Job Workers
Alluxio Job Workers是Alluxio文件系统的client, 负责运行Alluxio Job Master分配的任务。Job Worker接收在指定的文件系统位置上运行负载、持久化、复制、移动或拷贝操作的指令。
Alluxio job worker无需与普通worker并置,但建议将两者部署在同一个物理节点上。
Client
Alluxio client为用户提供了一个可与Alluxio server交互的网关。client发起与leading master节点的通信,来执行元数据操作,并从worker读取和写入存储在Alluxio中的数据。Alluxio支持Java中的原生文件系统API,并支持包括REST、Go和Python在内的多种客户端语言。此外,Alluxio支持与HDFS API以及Amazon S3 API兼容的API。
注意,Alluxio client不直接访问底层存储,而是通过Alluxio worker传输数据。
数据流:读操作
本节和下一节将介绍在典型配置下的Alluxio在常规读和写场景的行为:Alluxio与计算框架和应用程序并置部署,而底层存储一般是远端存储集群或云存储。
Alluxio位于存储和计算框架之间,可以作为数据读取的缓存层。本小节介绍Alluxio的不同缓存场景及其对性能的影响。
本地缓存命中
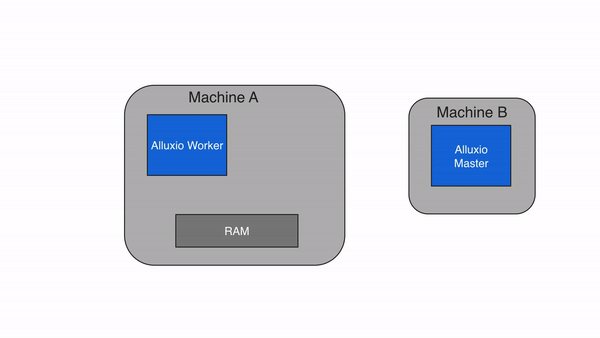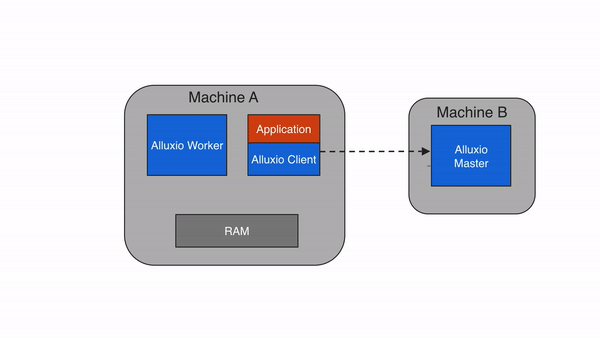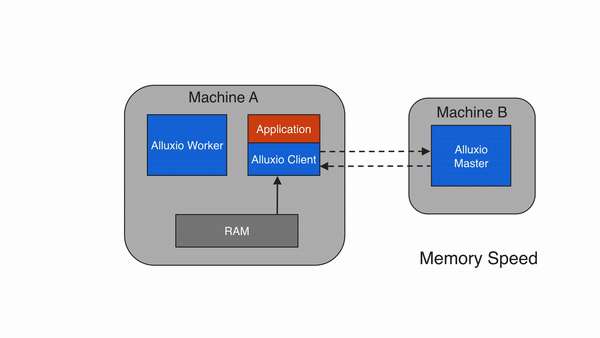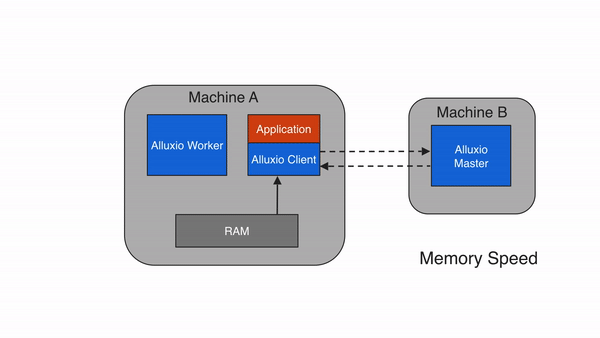
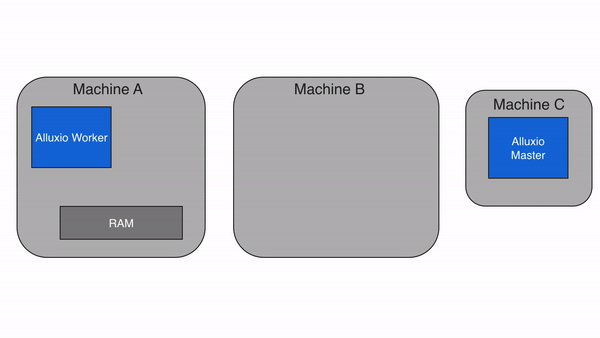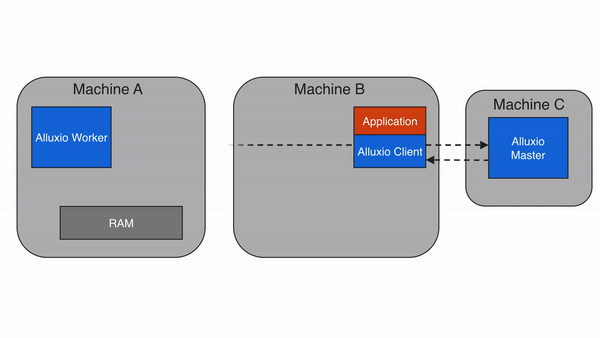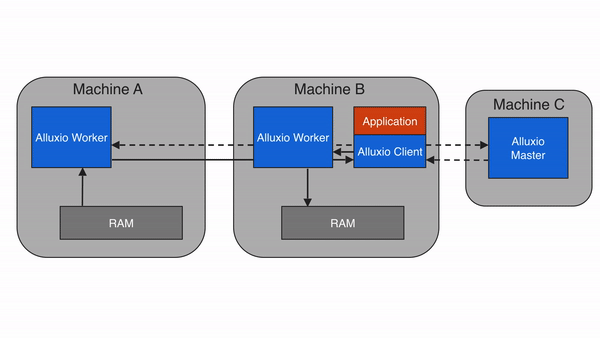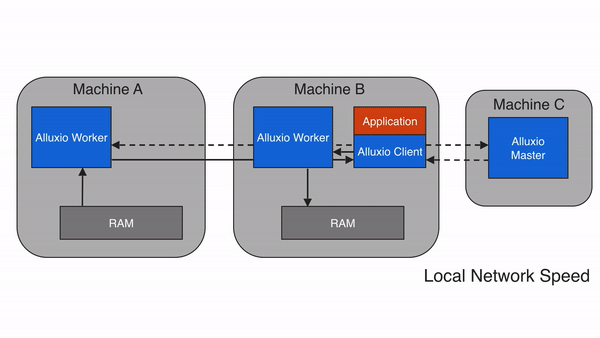
当应用程序需要读取的数据已经被缓存在本地Alluxio worker上时,即为本地缓存命中。应用程序通过Alluxio client请求数据访问后,Alluxio client会向 Alluxio master检索储存该数据的Alluxio worker位置。如果本地Alluxio worker存有该数据,Alluxio client将使用”短路读”绕过Alluxio worker,直接通过本地文件系统读取文件。短路读可避免通过TCP socket传输数据,并能提供内存级别的数据访问速度。短路读是从Alluxio读取数据最快的方式。
在默认情况下,短路读需要获得相应的本地文件系统操作权限。当Alluxio worker和client是在容器化的环境中运行时,可能会由于不正确的资源信息统计而无法实现短路读。在基于文件系统的短路读不可行的情况下,Alluxio可以基于domain socket的方式实现短路读,这时,Alluxio worker将通过预先指定的domain socket路径将数据传输到client。有关该主题的更多信息,请参见在Docker上运行Alluxio的文档。
此外,除内存外,Alluxio还可以管理其他存储介质(如SSD、HDD),因此本地访问速度可能因本地存储介质而异。要了解有关此主题的更多信息,请参见分层存储文档。
远程缓存命中
当Alluxio client请求的数据不在本地Alluxio worker上,但在集群中的某个远端Alluxio worker上时,Alluxio client将从远端worker读取数据。当client完成数据读取后,会指示本地worker(如果存在的话),在本地写入一个副本,以便将来再有相同数据的访问请求时,可以从本地内存中读取。远程缓存命中情况下的数据读取速度可以达到本地网络传输速度。由于Alluxio worker之间的网络速度通常比Alluxio worker与底层存储之间的速度快,因此Alluxio会优先从远端worker存储中读取数据。
缓存未命中
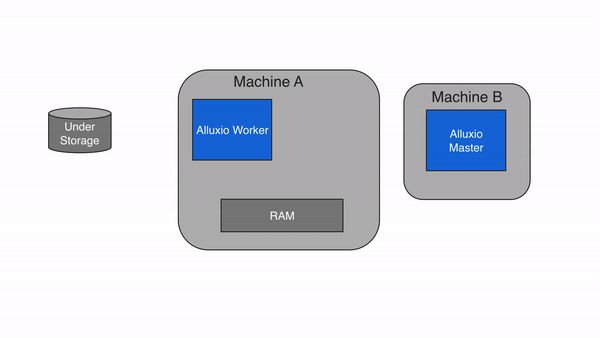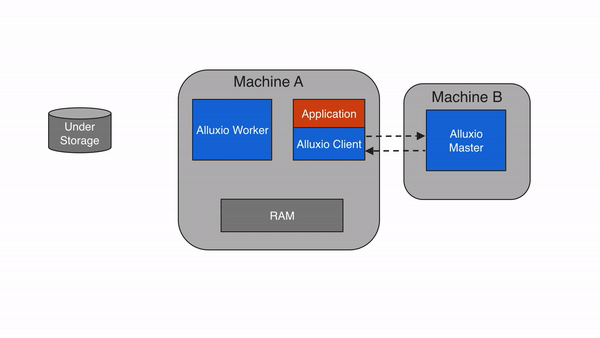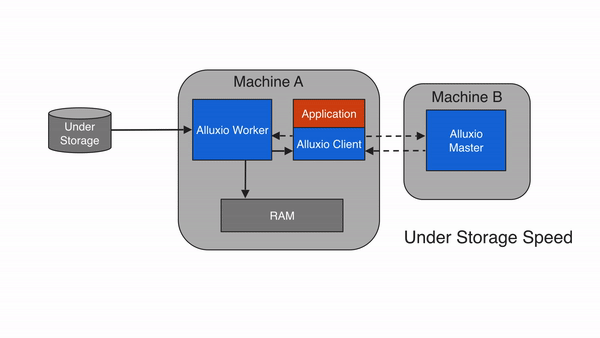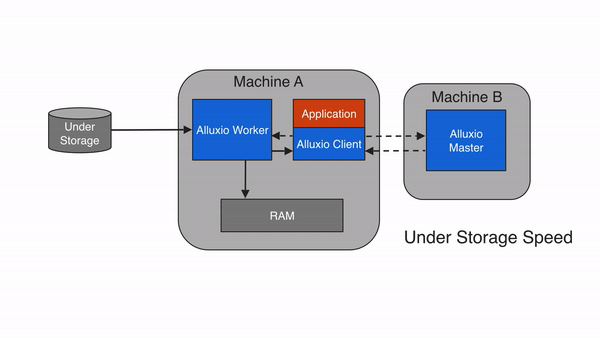
如果请求的数据不在Alluxio空间中,即发生请求未命中缓存的情况,应用程序将必须从底层存储中读取数据。Alluxio client会将读取请求委托给一个Alluxio worker(优先选择本地worker),从底层存储中读取和缓存数据。缓存未命中时,由于应用程序必须从底层存储系统中读取数据,因此一般会导致较大的延迟。缓存未命中通常发生在第一次读取数据时。
当Alluxio client仅读取block的一部分或者非顺序读取时,Alluxio client将指示Alluxio worker异步缓存整个block。这也称为异步缓存。异步缓存不会阻塞client,但如果Alluxio和存储系统之间的网络带宽成为瓶颈,则仍然可能会影响性能。我们可以通过设置 alluxio.worker.network.async.cache.manager.threads.max来调节异步缓存的影响。默认值为 8。
绕过缓存
用户可以通过将client中的配置项alluxio.user.file.readtype.default设置为NO_CACHE来关闭Alluxio中的缓存功能。
数据流:写操作
用户可以通过选择不同的写入类型来配置不同的写入方式。用户可以通过Alluxio API或在client中配置alluxio.user.file.writetype.default
来设置写入类型。本节将介绍不同写入类型的行为以及其对应用程序的性能影响。
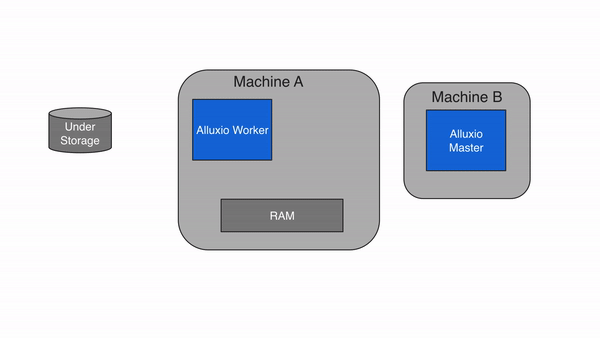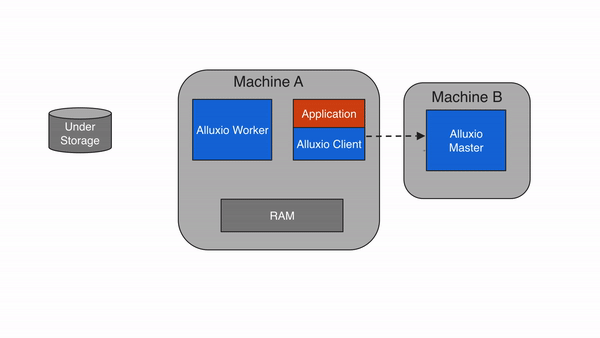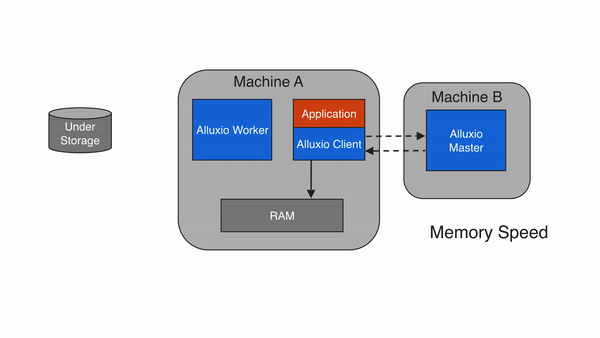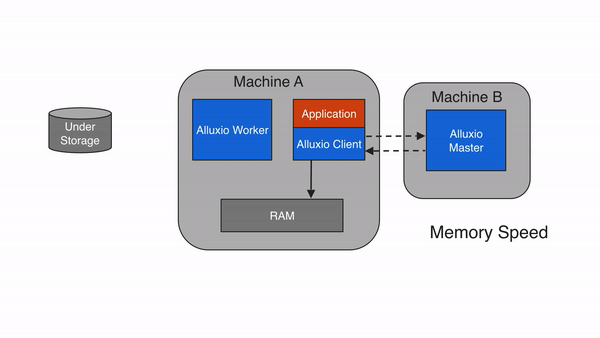
仅写Alluxio缓存(MUST_CACHE)
如果使用写入类型MUST_CACHE,Alluxio client仅将数据写入本地Alluxio worker,不会将数据写入底层存储系统。在写入期间,如果”短路写”可用,Alluxio client将直接将数据写入本地RAM盘上的文件中,绕过Alluxio worker,从而避免网络传输。由于数据没有持久化地写入底层存储,如果机器崩溃或需要通过释放缓存数据来进行较新的写入,则数据可能会丢失。因此,只有当可以容忍数据丢失的场景时(如写入临时数据),才考虑使用MUST_CACHE 类型的写入。
同步写缓存与持久化存储 (CACHE_THROUGH)
如果使用CACHE_THROUGH的写入类型,数据将被同步写入Alluxio worker和底层存储系统。Alluxio client将写入委托给本地worker,而worker将同时写入本地内存和底层存储。由于写入底层存储的速度通常比写入本地存储慢得多,因此client写入速度将与底层存储的写入速度相当。当需要保证数据持久性时,建议使用 CACHE_THROUGH 写入类型。该类型还会写入本地副本,本地存储的数据可供将来(读取)使用。
异步写回持久化存储(ASYNC_THROUGH)
Alluxio还提供了一种ASYNC_THROUGH写入类型。如果使用ASYNC_THROUGH,数据将被先同步写入Alluxio worker,再在后台持久化写入底层存储系统。 ASYNC_THROUGH可以以接近MUST_CACHE的内存速度提供数据写入,并能够完成数据持久化。从Alluxio 2.0开始,ASYNC_THROUGH已成为默认写入类型。
为了提供容错能力,还有一个重要配置项alluxio.user.file.replication.durable会和ASYNC_THROUGH一起使用。该配置项设置了在数据写入完成后但未被持久化到底层存储之前新数据在Alluxio中的目标复制级别,默认值为1。Alluxio将在后台持久化过程完成之前维持文件的目标复制级别,并在持久化完成之后收回Alluxio中的空间,因此数据只会被写入UFS一次。
如果使用ASYNC_THROUGH写入副本,并且在持久化数据之前出现包含副本的所有worker都崩溃的情况,则会导致数据丢失。
仅写持久化存储(THROUGH)
如果使用THROUGH,数据会同步写入底层存储,而不缓存到Alluxio worker。这种写入类型确保写入完成后数据将被持久化,但写入速度会受限于底层存储吞吐量。
数据一致性
无论写入类型如何,这些写入操作都会首先经由Alluxio master并在修改Alluxio文件系统之后再向client或应用程序返回成功,所以Alluxio 空间中的文件/目录始终是高度一致的。因此,只要相应的写入操作成功完成,不同的Alluxio client看到的数据将始终是最新的。
但是,对于需考虑UFS中数据状态的用户或应用程序而言,不同写入类型可能会导致差异:
MUST_CACHE不向UFS写入数据,因此Alluxio空间的数据永远不会与UFS一致。CACHE_THROUGH在向应用程序返回成功之前将数据同步写入Alluxio和UFS。- 如果写入UFS也是强一致的(例如,HDFS),且UFS中没有其他未经由Alluxio的更新,则Alluxio空间的数据将始终与UFS保持一致;
- 如果写入UFS是最终一致的(例如S3),则文件可能已成功写入Alluxio,但会稍晚才显示在UFS中。在这种情况下,由于Alluxio client总是会咨询强一致的Alluxio master,因此Alluxio client仍然会看到一致的文件系统;因此,尽管不同的Alluxio client始终在Alluxio空间中看到数据一致的状态,但在数据最终传输到UFS之前可能会存在数据不一致的阶段。
ASYNC_THROUGH将数据写入Alluxio并返回给应用程序,而Alluxio会将数据异步传输到UFS。从用户的角度来看,该文件可以成功写入Alluxio,但稍晚才会持久化到UFS中。THROUGH直接将数据写入UFS,不在Alluxio中缓存数据,但是,Alluxio知道文件的存在及其状态。因此元数据仍然是一致的。