

Running Spark on Alluxio
![]()

![]()
This guide describes how to configure Apache Spark to access Alluxio.
- Overview
- Prerequisites
- Basic Setup
- Examples: Use Alluxio as Input and Output
- Advanced Setup
- Advanced Usage
- Troubleshooting
Overview
Applications using Spark 1.1 or later can access Alluxio through its HDFS-compatible interface. Using Alluxio as the data access layer, Spark applications can transparently access data in many different types of persistent storage services (e.g., AWS S3 buckets, Azure Object Store buckets, remote HDFS deployments and etc). Data can be actively fetched or transparently cached into Alluxio to speed up I/O performance especially when the Spark deployment is remote to the data. In addition, Alluxio can help simplify the architecture by decoupling compute and physical storage. When the data path in persistent under storage is hidden from Spark, changes to under storage can be independent from application logic; meanwhile, as a near-compute cache, Alluxio can still provide compute frameworks data-locality.
Prerequisites
- Java 8 Update 60 or higher (8u60+), 64-bit.
- An Alluxio cluster is set up and is running.
This guide assumes the persistent under storage is a local HDFS deployment.
E.g., a line of
alluxio.master.mount.table.root.ufs=hdfs://localhost:9000/alluxio/is included in${ALLUXIO_HOME}/conf/alluxio-site.properties. Note that Alluxio supports many other under storage systems in addition to HDFS. To access data from any number of those systems is orthogonal to the focus of this guide but covered by Unified and Transparent Namespace. - Make sure that the Alluxio client jar is available.
This Alluxio client jar file can be found at
/<PATH_TO_ALLUXIO>/client/alluxio-2.9.5-client.jarin the tarball distribution downloaded from Alluxio download page. Alternatively, advanced users can compile this client jar from the source code by following the instructions.
Basic Setup
The Alluxio client jar must be distributed across the all nodes where Spark drivers
or executors are running.
Place the client jar on the same local path (e.g. /<PATH_TO_ALLUXIO>/client/alluxio-2.9.5-client.jar) on each node.
The Alluxio client jar must be in the classpath of all Spark drivers and executors
in order for Spark applications to access Alluxio.
Add the following line to spark/conf/spark-defaults.conf on every node running Spark.
Also, make sure the client jar is copied to every node running Spark.
spark.driver.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.9.5-client.jar
spark.executor.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.9.5-client.jar
Examples: Use Alluxio as Input and Output
This section shows how to use Alluxio as input and output sources for your Spark applications.
Access Data Only in Alluxio
Copy local data to the Alluxio file system. Put the LICENSE file into Alluxio,
assuming you are in the Alluxio installation directory:
$ ./bin/alluxio fs copyFromLocal LICENSE /Input
Run the following commands from spark-shell, assuming the Alluxio Master is
running on localhost:
val s = sc.textFile("alluxio://localhost:19998/Input")
val double = s.map(line => line + line)
double.saveAsTextFile("alluxio://localhost:19998/Output")
You may also open your browser and check http://localhost:19999/browse.
There should be an output directory /Output which contains the doubled content
of the input file Input.
Access Data in Under Storage
Alluxio transparently fetches data from the under storage system, given the exact path. For this section, HDFS is used as an example of a distributed under storage system.
Put a file Input_HDFS into HDFS:
$ hdfs dfs -copyFromLocal -f ${ALLUXIO_HOME}/LICENSE hdfs://localhost:9000/alluxio/Input_HDFS
At this point, Alluxio does not know about this file since it was added to HDFS directly.
Verify this by going to the web UI.
Run the following commands from spark-shell assuming Alluxio Master is running
on localhost:
val s = sc.textFile("alluxio://localhost:19998/Input_HDFS")
val double = s.map(line => line + line)
double.saveAsTextFile("alluxio://localhost:19998/Output_HDFS")
Open your browser and check http://localhost:19999/browse.
There should be an output directory Output_HDFS which contains the doubled
content of the input file Input_HDFS.
Also, the input file Input_HDFS now will be 100% loaded in the Alluxio file
system space.
Advanced Setup
Configure Spark for Alluxio with HA
When connecting to an HA-enabled Alluxio cluster using internal leader election,
set the alluxio.master.rpc.addresses property via the Java options in
${SPARK_HOME}/conf/spark-defaults.conf so Spark
applications know which Alluxio masters to connect to and how to identify the
leader. For example:
spark.driver.extraJavaOptions -Dalluxio.master.rpc.addresses=master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998
spark.executor.extraJavaOptions -Dalluxio.master.rpc.addresses=master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998
Alternatively, add the property to the Hadoop configuration file
${SPARK_HOME}/conf/core-site.xml:
<configuration>
<property>
<name>alluxio.master.rpc.addresses</name>
<value>master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998</value>
</property>
</configuration>
Users can also configure Spark to connect to an Alluxio HA cluster using Zookeeper-based leader election. Refer to HA mode client configuration parameters.
Customize Alluxio User Properties for Individual Spark Jobs
Spark users can use pass JVM system properties to set Alluxio properties on to Spark jobs by
adding "-Dproperty=value" to spark.executor.extraJavaOptions for Spark executors and
spark.driver.extraJavaOptions for Spark drivers.
For example, to submit a Spark job with that uses the Alluxio CACHE_THROUGH write type:
$ spark-submit \
--conf 'spark.driver.extraJavaOptions=-Dalluxio.user.file.writetype.default=CACHE_THROUGH' \
--conf 'spark.executor.extraJavaOptions=-Dalluxio.user.file.writetype.default=CACHE_THROUGH' \
...
To customize Alluxio client-side properties for a Spark job, see how to configure Spark Jobs.
Note that in client mode you need to set --driver-java-options "-Dalluxio.user.file.writetype.default=CACHE_THROUGH"
instead of --conf spark.driver.extraJavaOptions=-Dalluxio.user.file.writetype.default=CACHE_THROUGH
(see explanation).
Advanced Usage
Access Data from Alluxio with HA
If Spark configured using the instructions in Configure Spark for Alluxio with HA,
you can write URIs using the alluxio:/// scheme without specifying cluster
information in the authority.
This is because in HA mode, the address of leader Alluxio master will be served
by the internal leader election or by the configured Zookeeper service.
val s = sc.textFile("alluxio:///Input")
val double = s.map(line => line + line)
double.saveAsTextFile("alluxio:///Output")
Alternatively, users may specify the HA authority directly in the URI without any configuration setup. For example, specify the master rpc addresses in the URI to connect to Alluxio configured for HA using internal leader election:
val s = sc.textFile("alluxio://master_hostname_1:19998;master_hostname_2:19998;master_hostname_3:19998/Input")
val double = s.map(line => line + line)
double.saveAsTextFile("alluxio://master_hostname_1:19998;master_hostname_2:19998;master_hostname_3:19998/Output")
Note that you must use semicolons rather than commas to separate different addresses to refer a URI of Alluxio in HA mode in Spark. Otherwise, the URI will be considered invalid by Spark. Please refer to the instructions in HA authority.
Cache RDDs into Alluxio
Storing RDDs in Alluxio memory is as simple as saving the RDD file to Alluxio. Two common ways to save RDDs as files in Alluxio are
saveAsTextFile: writes the RDD as a text file, where each element is a line in the file,saveAsObjectFile: writes the RDD out to a file, by using Java serialization on each element.
The saved RDDs in Alluxio can be read again (from memory) by using sc.textFile or
sc.objectFile respectively.
// as text file
rdd.saveAsTextFile("alluxio://localhost:19998/rdd1")
rdd = sc.textFile("alluxio://localhost:19998/rdd1")
// as object file
rdd.saveAsObjectFile("alluxio://localhost:19998/rdd2")
rdd = sc.objectFile("alluxio://localhost:19998/rdd2")
See the blog article “Effective Spark RDDs with Alluxio”.
Cache Dataframes in Alluxio
Storing Spark DataFrames in Alluxio memory is as simple as saving the DataFrame as a
file to Alluxio.
DataFrames are commonly written as parquet files, with df.write.parquet().
After the parquet is written to Alluxio, it can be read from memory by using
spark.read.parquet() (or sqlContext.read.parquet() for older versions of Spark).
df.write.parquet("alluxio://localhost:19998/data.parquet")
df = spark.read.parquet("alluxio://localhost:19998/data.parquet")
See the blog article “Effective Spark DataFrames with Alluxio”.
Troubleshooting
Logging Configuration
You may configure Spark’s application logging for debugging purposes. The Spark documentation explains how to configure logging for a Spark application.
If you are using YARN then there is a separate section which explains how to configure logging with YARN for a Spark application.
Incorrect Data Locality Level of Spark Tasks
If Spark task locality is ANY while it should be NODE_LOCAL, it is probably
because Alluxio and Spark use different network address representations.
One of them them may use hostname while another uses IP address.
Refer to JIRA ticket SPARK-10149
for more details, where you can find solutions from the Spark community.
Note: Alluxio workers use hostnames to represent network addresses to be consistent with HDFS. There is a workaround when launching Spark to achieve data locality. Users can explicitly specify hostnames by using the following script offered in Spark. Start the Spark Worker in each slave node with slave-hostname:
$ ${SPARK_HOME}/sbin/start-worker.sh -h <slave-hostname> <spark master uri>
Note for older versions of Spark the script is called start-slave.sh.
For example:
$ ${SPARK_HOME}/sbin/start-worker.sh -h simple30 spark://simple27:7077
You can also set the SPARK_LOCAL_HOSTNAME in $SPARK_HOME/conf/spark-env.sh
to achieve this. For
example:
SPARK_LOCAL_HOSTNAME=simple30
Either way, the Spark Worker addresses become hostnames and Locality Level
becomes NODE_LOCAL as shown in Spark WebUI below.

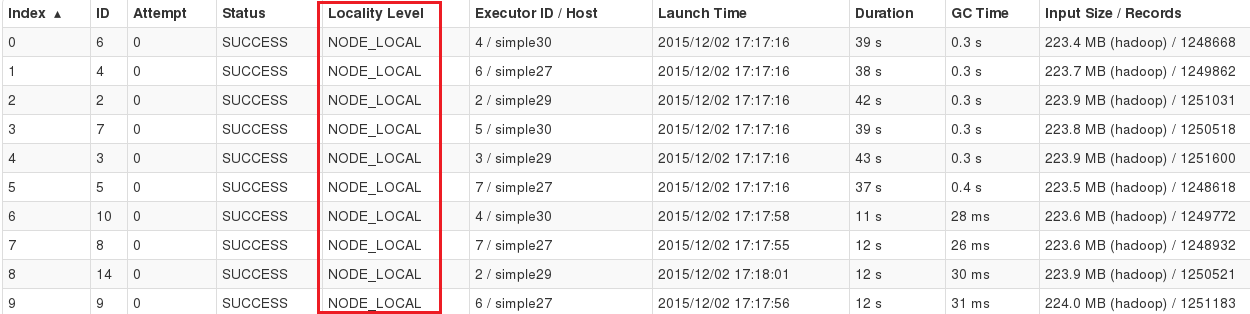
Data Locality of Spark Jobs on YARN
To maximize the amount of locality your Spark jobs attain, you should use as many executors as possible, hopefully at least one executor per node. It is recommended to co-locate Alluxio workers with the Spark executors.
When a Spark job is run on YARN, Spark launches its executors without taking data locality into account. Spark will then correctly take data locality into account when deciding how to distribute tasks to its executors.
For example, if host1 contains blockA and a job using blockA is launched
on the YARN cluster with --num-executors=1, Spark might place the only
executor on host2 and have poor locality.
However, if --num-executors=2 and executors are started on host1 and
host2, Spark will be smart enough to prioritize placing the job on host1.
Class alluxio.hadoop.FileSystem not found Issues with SparkSQL and Hive Metastore
To run the spark-shell with the Alluxio client, the Alluxio client jar will
must be added to the classpath of the Spark driver and Spark executors, as
described earlier.
However, sometimes SparkSQL may fail to save tables to the Hive Metastore
(location in Alluxio), with an error message similar to the following:
org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:java.lang.RuntimeException: java.lang.ClassNotFoundException: Class alluxio.hadoop.FileSystem not found)
The recommended solution is to configure
spark.sql.hive.metastore.sharedPrefixes.
In Spark 1.4.0 and later, Spark uses an isolated classloader to load java
classes for accessing the Hive Metastore.
The isolated classloader ignores certain packages and allows the main
classloader to load “shared” classes (the Hadoop HDFS client is one of these
“shared” classes).
The Alluxio client should also be loaded by the main classloader, and you can
append the alluxio package to the configuration parameter
spark.sql.hive.metastore.sharedPrefixes to inform Spark to load Alluxio with
the main classloader.
For example, the parameter may be set in spark/conf/spark-defaults.conf:
spark.sql.hive.metastore.sharedPrefixes=com.mysql.jdbc,org.postgresql,com.microsoft.sqlserver,oracle.jdbc,alluxio
java.io.IOException: No FileSystem for scheme: alluxio Issue with Spark on YARN
If you use Spark on YARN with Alluxio and run into the exception
java.io.IOException: No FileSystem for scheme: alluxio, please add the
following content to ${SPARK_HOME}/conf/core-site.xml:
<configuration>
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
</configuration>