

Architecture
![]()

![]()
Architecture Overview
Alluxio serves as a new data access layer in the big data and machine learning ecosystem. It resides between any persistent storage systems such as Amazon S3, Microsoft Azure Object Store, Apache HDFS, or OpenStack Swift, and computation frameworks such as Apache Spark, Presto, or Hadoop MapReduce. Note that Alluxio itself is not a persistent storage system. Using Alluxio as the data access layer provides multiple benefits:
-
For user applications and computation frameworks, Alluxio provides fast storage, and facilitates data sharing and locality between applications, regardless of the computation engine used. As a result, Alluxio can serve data at memory speed when it is local or at the speed of the computation cluster network when data is in Alluxio. Data is only read once from the under storage system when accessed for the first time. Data access is significantly accelerated when access to the under storage is slow. To achieve the best performance, Alluxio is recommended to be deployed alongside a cluster’s computation framework.
-
For under storage systems, Alluxio bridges the gap between big data applications and traditional storage systems, expanding the set of workloads available to utilize the data. Since Alluxio hides the integration of under storage systems from applications, any under storage can support any of the applications and frameworks running on top of Alluxio. When mounting multiple under storage systems simultaneously, Alluxio serves as a unifying layer for any number of varied data sources.
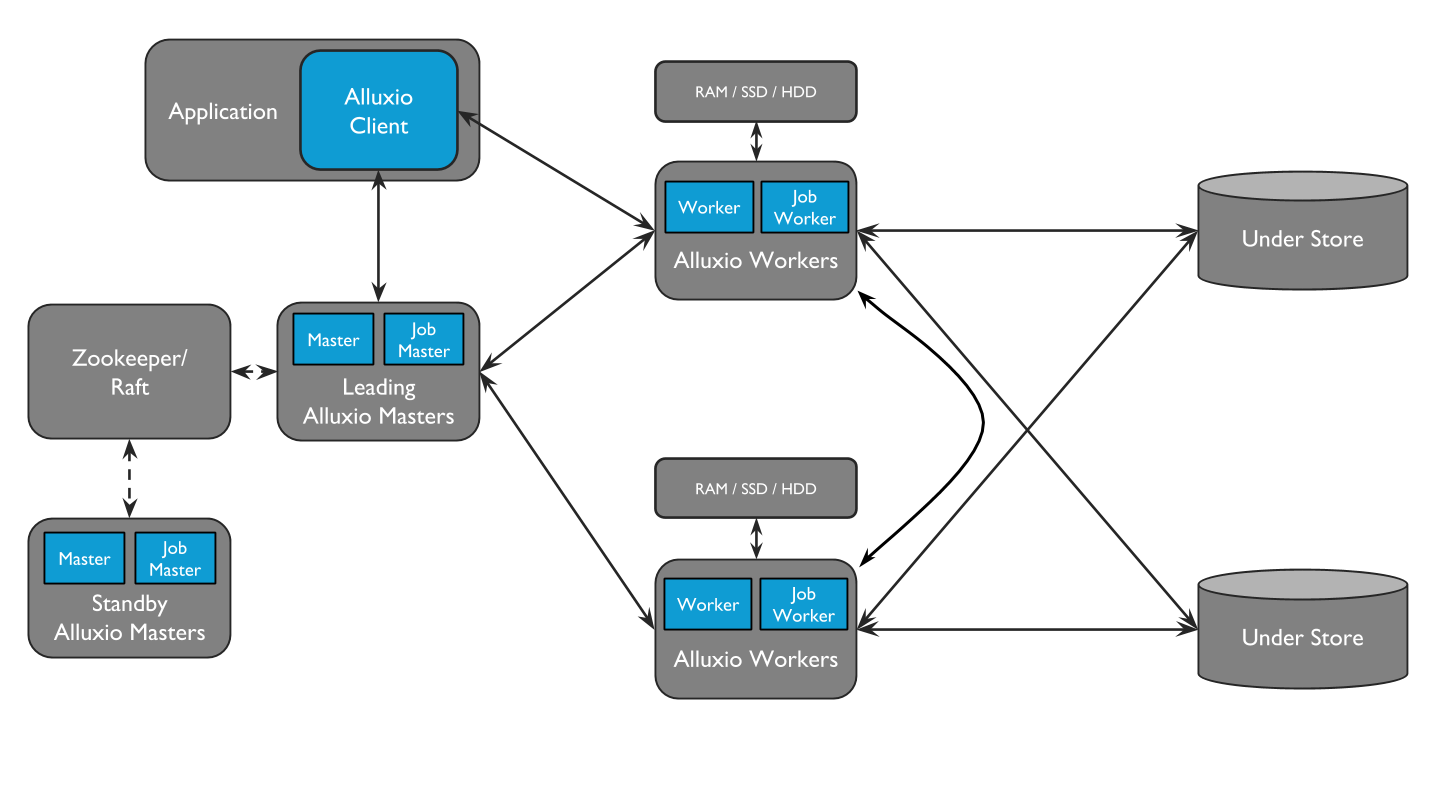
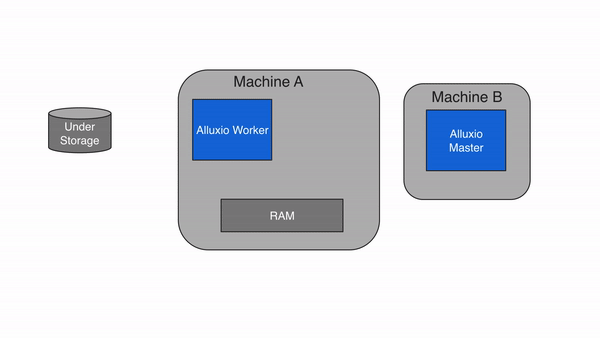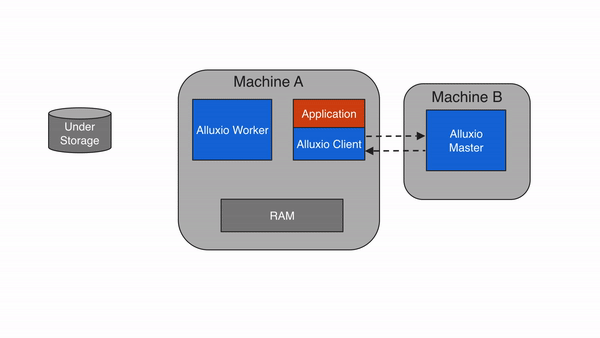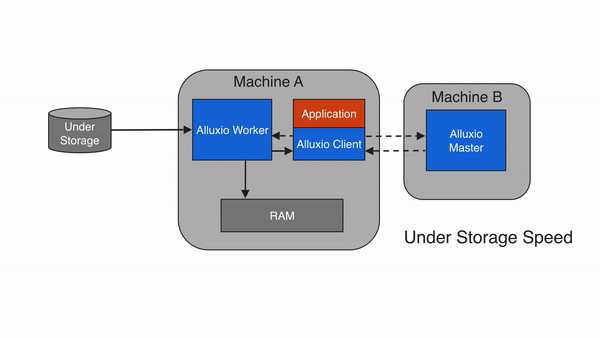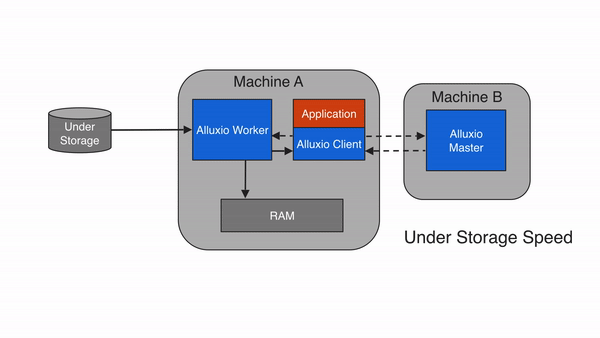
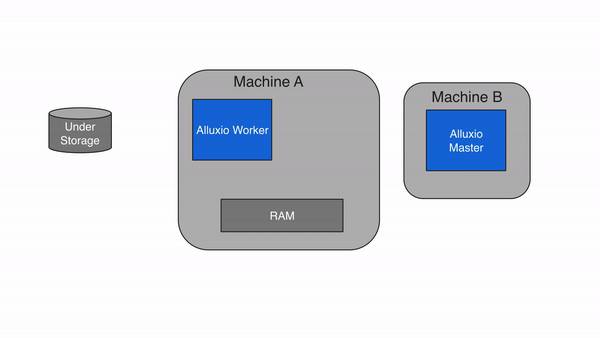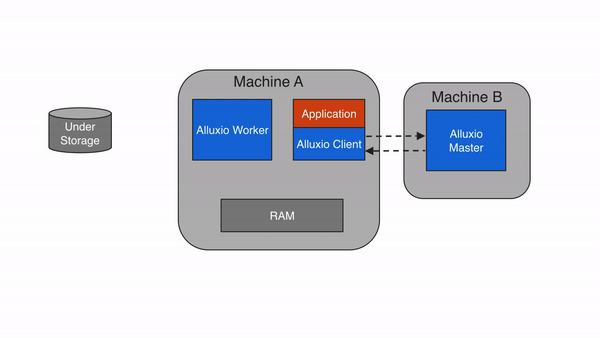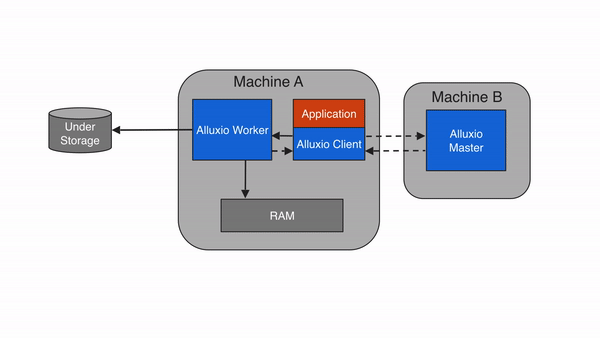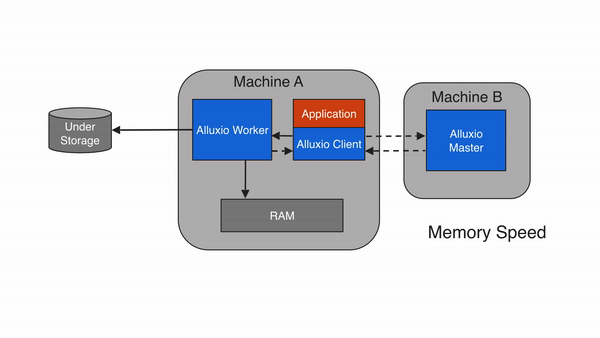
Alluxio can be divided into three components: masters, workers, and clients. A typical cluster consists of a single leading master, standby masters, a job master, standby job masters, workers, and job workers. The master and worker processes constitute the Alluxio servers, which are the components a system administrator would maintain. Clients are used to communicate with the Alluxio servers by applications such as Spark or MapReduce jobs, the Alluxio CLI, or the Alluxio FUSE layer.
Alluxio Job Masters and Job Workers can be separated into a separate function which is termed the Job Service. The Alluxio Job Service is a lightweight task scheduling framework responsible for assigning a number of different types of operations to Job Workers. Those tasks include
- Loading data into Alluxio from a UFS
- Persisting data to a UFS
- Replicating files within Alluxio
- Moving or copying data between UFS or Alluxio locations
The job service is designed so that all job related processes don’t necessarily need to be located with the rest of the Alluxio cluster. However, we do recommend that job workers are co-located with a corresponding Alluxio worker as it provides lower latency for RPCs and data transfer.
Masters
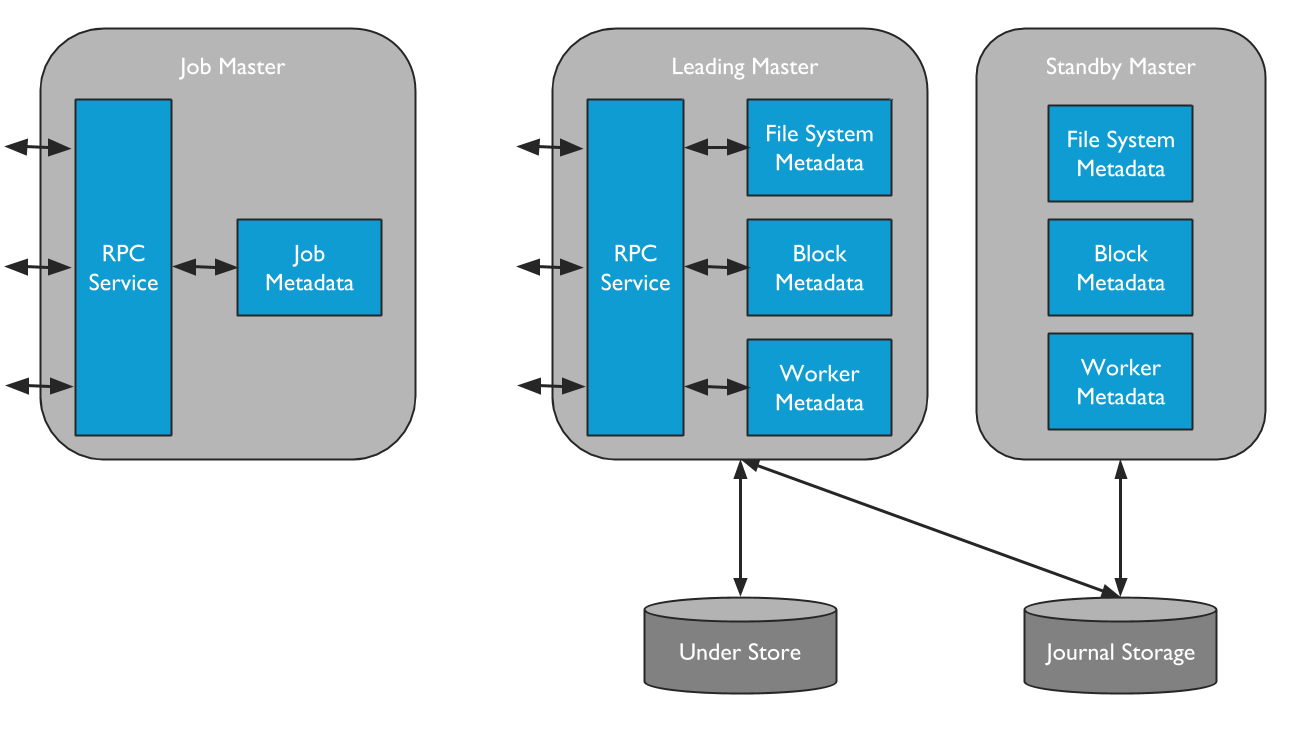
Alluxio contains of two separate types of master processes. One is the Alluxio Master. The Alluxio Master serves all user requests and journals file system metadata changes. The Alluxio Job Master is the process which serves as a lightweight scheduler for file system operations which are then executed on Alluxio Job Workers
The Alluxio Master can be deployed as one leading master and several standby masters for fault tolerance. When the leading master goes down, a standby master is elected to become the new leading master.
Leading Master
Only one master process can be the leading master in an Alluxio cluster. The leading master is responsible for managing the global metadata of the system. This includes file system metadata (e.g. the file system inode tree), block metadata (e.g. block locations), and worker capacity metadata (free and used space). The leading master will only ever query under storage for metadata. Application data will never be routed through the master. Alluxio clients interact with the leading master to read or modify this metadata. All workers periodically send heartbeat information to the leading master to maintain their participation in the cluster. The leading master does not initiate communication with other components; it only responds to requests via RPC services. The leading master records all file system transactions to a distributed persistent storage location to allow for recovery of master state information; the set of records is referred to as the journal.
Standby Masters
Standby masters are launched on different servers to provide fault-tolerance when running Alluxio in HA mode. Standby masters read journals written by the leading master to keep their own copies of the master state up-to-date. They also write journal checkpoints for faster recovery in the future. However, they do not process any requests from other Alluxio components. After leading master fail-over, the standby masters will re-elect the new leading master after.
Secondary Masters (for UFS journal)
When running a single Alluxio master without HA mode with UFS journal, one can start a secondary master on the same server as the leading master to write journal checkpoints. Note that, the secondary master is not designed to provide high availability but offload the work from the leading master for fast recovery. Different from standby masters, a secondary master can never upgrade to a leading master.
Job Masters
The Alluxio Job Master is a standalone process which is responsible for scheduling a number of more heavyweight file system operations asynchronously within Alluxio. By separating the need for the leading Alluxio Master to execute these operations within the same process the Alluxio Master utilizes less resources and is able to serve more clients within a shorter period. Additionally, it provides an extensible framework for more complicated operations to be added in the future.
The Alluxio Job Master accepts requests to perform the above operations and schedules the operations to be executed on Alluxio Job Workers which act as clients to the Alluxio file system. The job workers are discussed more in the following section.
Workers
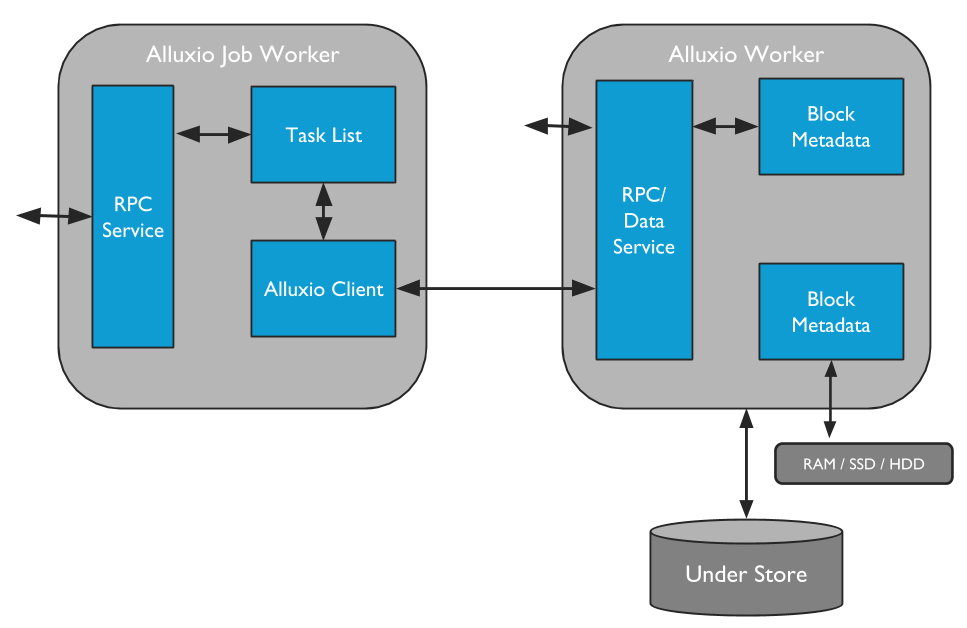
Alluxio Workers
Alluxio workers are responsible for managing user-configurable local resources allocated to Alluxio (e.g. memory, SSDs, HDDs). Alluxio workers store data as blocks and serve client requests that read or write data by reading or creating new blocks within their local resources. Workers are only responsible for managing blocks; the actual mapping from files to blocks is only stored by the master.
Workers perform data operations on the under store. This brings two important benefits:
- The data read from the under store can be stored in the worker and be immediately available to other clients.
- The client can be lightweight and does not depend on the under storage connectors.
Because RAM usually offers limited capacity, blocks in a worker can be evicted when space is full. Workers employ eviction policies to decide which data to keep in the Alluxio space. For more on this topic, check out the documentation for Tiered Storage.
Alluxio Job Workers
Alluxio Job Workers are clients of the Alluxio file system. They are responsible for running tasks given to them by the Alluxio Job Master. Job Workers receive instructions to run load, persist, replicate, move, or copy operations on any given file system locations.
Alluxio job workers don’t necessarily have to be co-located with normal workers, but it is recommended to have both on the same physical node.
Client
The Alluxio client provides users a gateway to interact with the Alluxio servers. It initiates communication with the leading master to carry out metadata operations and with workers to read and write data that is stored in Alluxio. Alluxio supports a native file system API in Java and bindings in multiple languages including REST, Go, and Python. Alluxio also supports APIs that are compatible with the HDFS API and the Amazon S3 API.
Note that Alluxio clients never directly access the under storage systems. Data is transmitted through Alluxio workers.
Data flow: Read
This and the next section describe the behavior of common read and write scenarios based on a typical Alluxio configuration: Alluxio is co-located with a compute framework and applications and the persistent storage system is either a remote storage cluster or cloud-based storage.
Residing between the under storage and computation framework, Alluxio serves as a caching layer for data reads. This subsection introduces different caching scenarios and their implications on performance.
Local Cache Hit
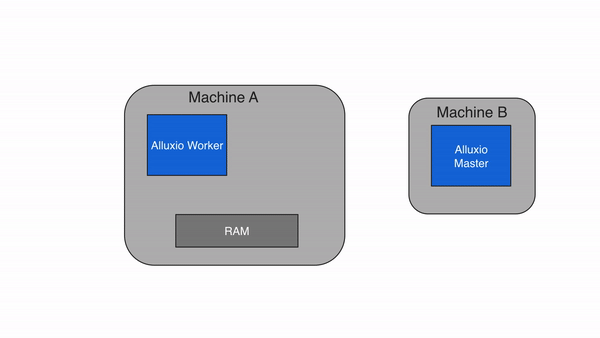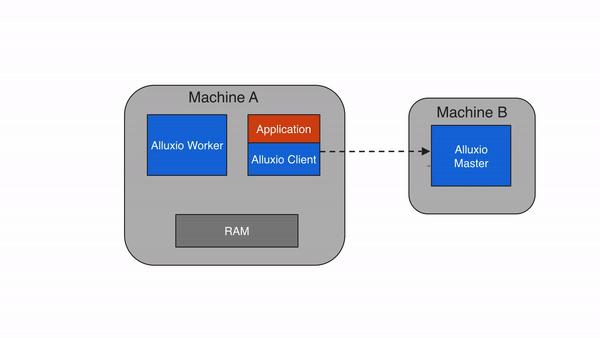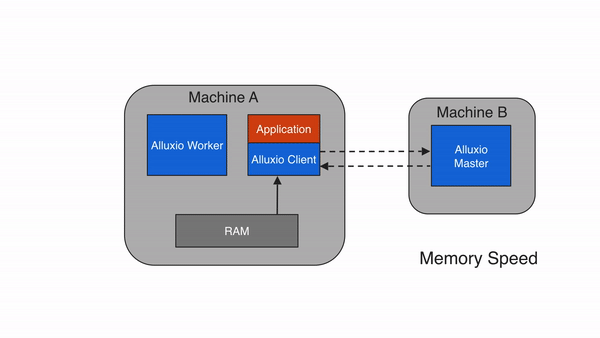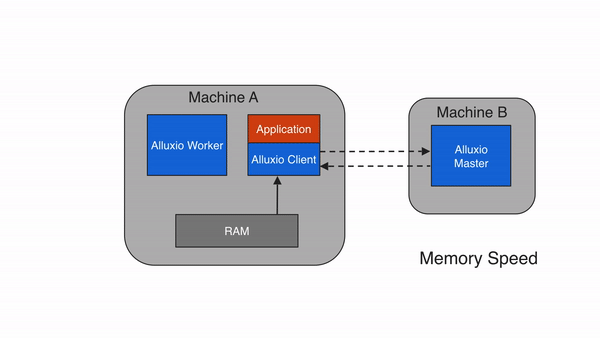
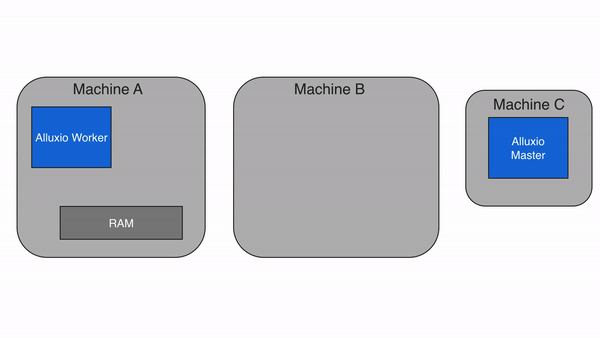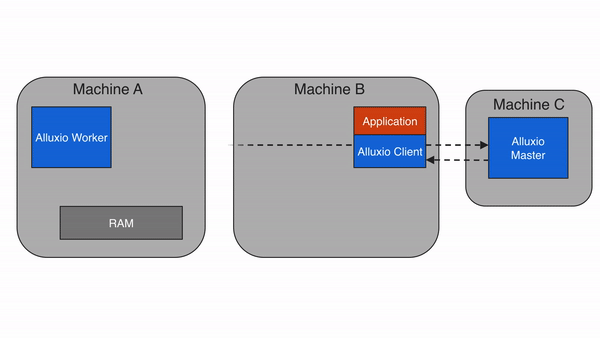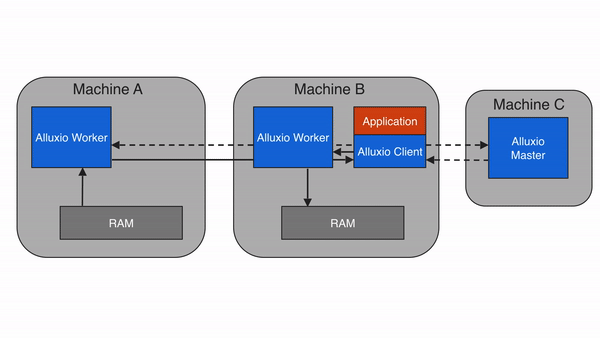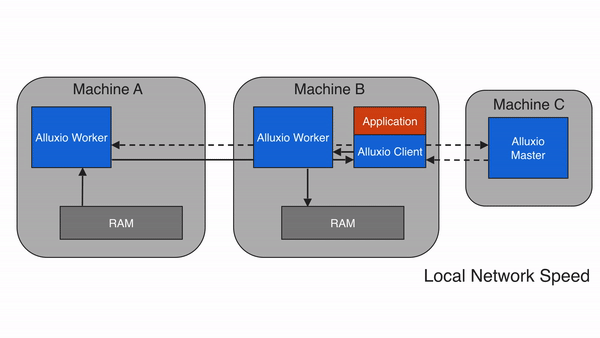
A local cache hit occurs when the requested data resides on the local Alluxio worker. For example, if an application requests data access through the Alluxio client, the client asks the Alluxio master for the worker location of the data. If the data is locally available, the Alluxio client uses a “short-circuit” read to bypass the Alluxio worker and read the file directly via the local file system. Short-circuit reads avoid data transfer over a TCP socket and provide the data access directly. Short-circuit reads are fastest way of reading data out of Alluxio.
By default, short-circuit reads use local file system operations which require permissive permissions. This is sometimes impossible when the worker and client are containerized due to incorrect resource accounting. In cases where the default short-circuit is not feasible, Alluxio provides domain socket based short-circuit in which the worker transfers data to the client through a predesignated domain socket path. For more information on this topic, please check out the instructions on running Alluxio on Docker.
Also, note that Alluxio can manage other storage media (e.g. SSD, HDD) in addition to memory, so local data access speed may vary depending on the local storage media. To learn more about this topic, please refer to the tiered storage document.
Remote Cache Hit
When requested data is stored in Alluxio, but not on a client’s local worker, the client will perform a remote read from a worker that does have the data. After the client finishes reading the data, the client instructs the local worker, if present, to create a copy locally so that future reads of the same data can be served locally. Remote cache hits provide network-speed data reads. Alluxio prioritizes reading from remote workers over reading from under storage because the network speed between Alluxio workers is typically faster than the speed between Alluxio workers and the under storage.
Cache Miss
If the data is not available within the Alluxio space, a cache miss occurs and the application will have to read the data from the under storage. The Alluxio client delegates the read from a UFS to a worker, preferably a local worker. This worker reads and caches the data from the under storage. Cache misses generally cause the largest delay because data must be fetched from the under storage. A cache miss is expected when reading data for the first time.
When the client reads only a portion of a block or
reads the block non-sequentially, the client will instruct the worker to cache the
full block asynchronously. This is called asynchronous caching.
Asynchronous caching does not block the client, but may still impact
performance if the network bandwidth between Alluxio and the under storage
system is a bottleneck. You can tune the impact of asynchronous caching by setting
alluxio.worker.network.async.cache.manager.threads.max on your workers.
The default value is 8.
Cache Skip
It is possible to turn off caching in Alluxio by setting the property
alluxio.user.file.readtype.default
in the client to NO_CACHE.
Data flow: Write
Users can configure how data should be written by choosing from different write
types. The write type can be set either through the Alluxio API or by
configuring the property
alluxio.user.file.writetype.default
in the client. This section describes the behaviors of different write types as
well as the performance implications to the applications.
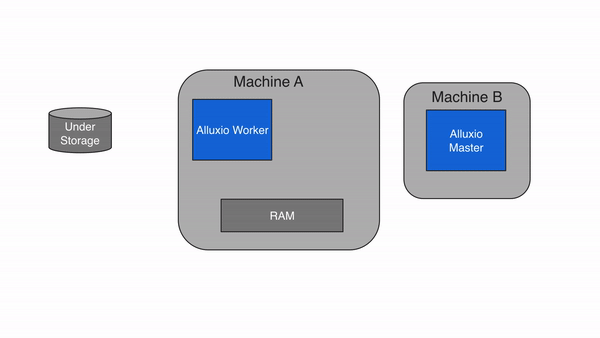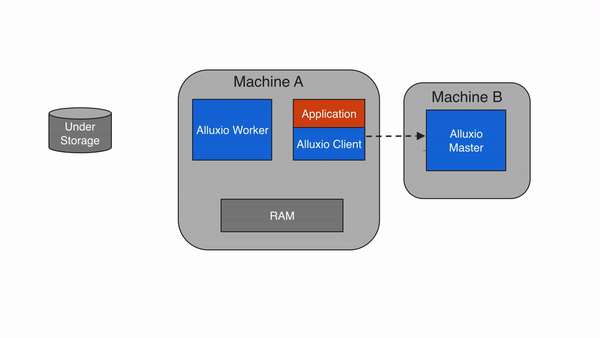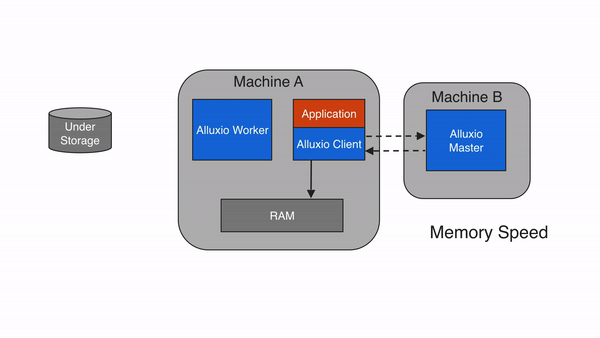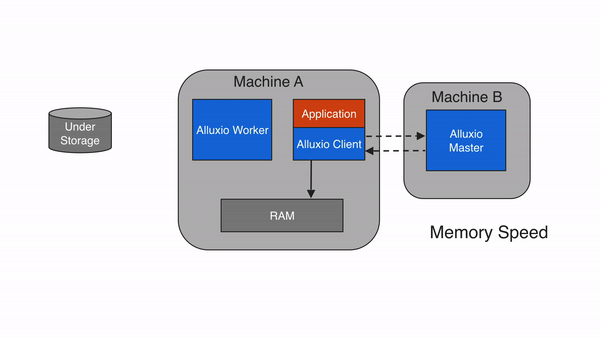
Write to Alluxio only (MUST_CACHE)
With a write type of MUST_CACHE, the Alluxio client only writes to the local
Alluxio worker and no data will be written to the under storage. During the
write, if short-circuit write is available, Alluxio client directly writes
to the file on the local RAM disk, bypassing the Alluxio worker to avoid
network transfer. Since the data is not persisted to the under storage,
data can be lost if the machine crashes or data needs to be freed up for newer writes.
The MUST_CACHE setting is useful for writing temporary data when data loss can be tolerated.
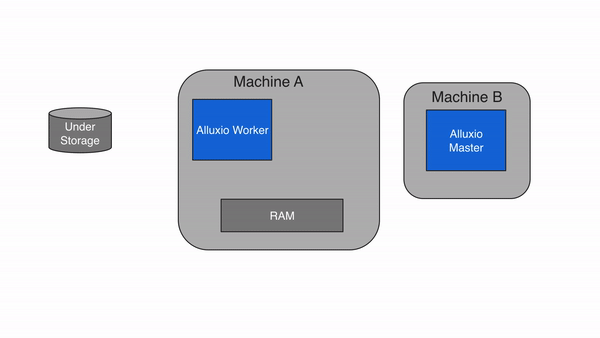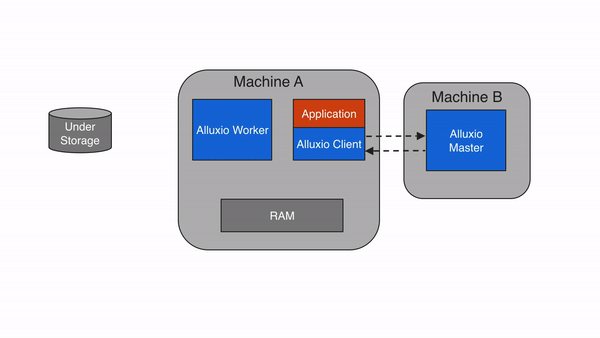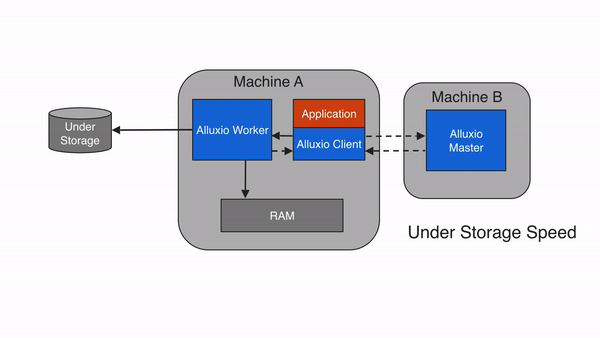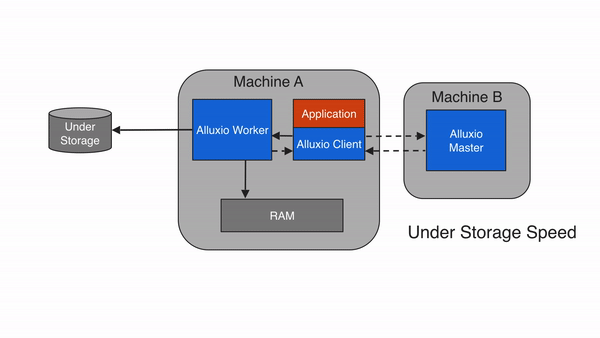
Write through to UFS (CACHE_THROUGH)
With the write type of CACHE_THROUGH, data is written synchronously to an
Alluxio worker and the under storage system. The Alluxio client delegates the
write to the local worker and the worker simultaneously writes to both
local memory and the under storage. Since the under storage is typically
slower to write to than the local storage, the client write speed will
match the write speed of the under storage. The CACHE_THROUGH write type is
recommended when data persistence is required. A local copy is also written so
any future reads of the data can be served from local memory directly.
Write back to UFS (ASYNC_THROUGH)
Alluxio provides a write type of ASYNC_THROUGH. With ASYNC_THROUGH,
data is written synchronously to an Alluxio worker first, and persisted to the
under storage in the background. ASYNC_THROUGH can provide data write at a speed
close to MUST_CACHE, while still being able to persist the data. Since Alluxio 2.0,
ASYNC_THROUGH is the default write type.
To provide fault tolerance, one important property working with ASYNC_THROUGH is
alluxio.user.file.replication.durable. This property sets a target replication level of new data
in Alluxio after write completes but before the data is persisted to the under storage, with a
default value 1. Alluxio will maintain the target replication level of the file before the
background persist process completes, and reclaim the space in Alluxio afterwards, so the data will only be written to the UFS once.
If you are writing replica with ASYNC_THROUGH and all worker with the copies crash before you persist the data, then you will incur a data loss.
Write to UFS Only (THROUGH)
With THROUGH, data is written to under storage synchronously without being cached to Alluxio
workers. This write type ensures that data will be persisted after the write completes, but the
speed is limited by the under storage throughput.
Data consistency
Regardless of write types, files/dirs in Alluxio space are always strongly consistent as all these write operations will go through Alluxio master first and modify Alluxio file system before returning success to the client/applications. Therefore, different Alluxio clients will always see the latest update as long as its corresponding write operation completes successfully.
However, for users or applications taking the state in UFS into account, it might be different across write types:
MUST_CACHEwrites no data to UFS, so Alluxio space is never consistent with UFS.CACHE_THROUGHwrites data synchronously to Alluxio and UFS before returning success to applications.- If writing to UFS is also strongly consistent (e.g., HDFS), Alluxio space will be always consistent with UFS if there is no other out-of-band updates in UFS;
- if writing to UFS is eventually consistent (e.g. S3), it is possible that the file is written successfully to Alluxio but shown up in UFS later. In this case, Alluxio clients will still see consistent file system as they will always consult Alluxio master which is strongly consistent; Therefore, there may be a window of inconsistence before data finally propagated to UFS despite different Alluxio clients still see consistent state in Alluxio space.
ASYNC_THROUGHwrites data to Alluxio and return to applications, leaving Alluxio to propagate the data to UFS asynchronously. From users perspective, the file can be written successfully to Alluxio, but get persisted in UFS later.THROUGHwrites data to UFS directly without caching the data in Alluxio, however, Alluxio knows the files and its status. Thus the metadata is still consistent.