

应用场景
![]()

![]()
世界上许多头部企业都在生产中部署Alluxio,以从数据中获取价值。我们在 Powered-By 页面中列出了部分企业。下面我们将介绍一些最常见的 Alluxio 应用场景。
应用场景1:加速云上分析和AI 作业
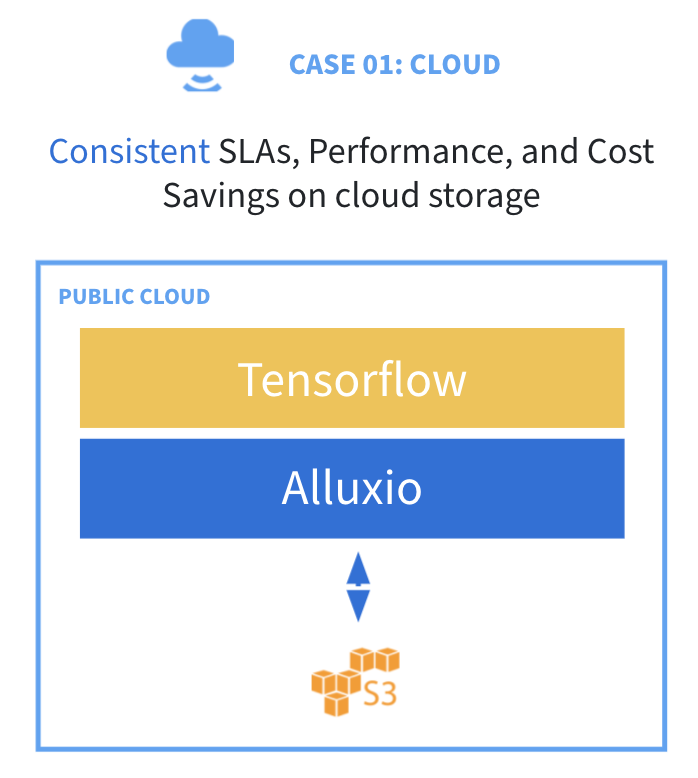
许多企业都在公有云(AWS S3、Google Cloud 或 Microsoft Azure)对象存储上运行分析和机器学习负载(Spark、Presto、Hive、Tensorflow 等)。
虽然云对象存储通常性价比更高,易于使用和扩展,但也存在一些挑战:
- 性能不稳定,难以实现SLA一致
- 元数据操作昂贵,拖慢负载运行
- 自带缓存对于短暂运行的集群无效
Alluxio 通过提供智能多级缓存和元数据管理来解决这些挑战。在计算集群上部署 Alluxio 有助于:
- 实现分析引擎的性能稳定
- 降低AI训练时间和成本
- 去除重复存储带来的成本
- 对于短暂运行的工作负载实现集群外缓存
本应用场景案例参见 Electronic Arts(美国艺电)。
应用场景2:加速本地对象存储的分析和AI作业

在本地部署的对象存储上运行数据驱动型应用会带来以下挑战:
- 分析和AI负载性能差
- 缺乏对主流框架的原生支持
- 元数据操作成本高昂且性能低下
Alluxio 通过提供缓存和 API 转换功能来解决这些问题。在应用端部署 Alluxio 带来以下益处:
- 分析和AI负载性能提升
- 可灵活实现存储隔离
- 支持多个API,不影响终端用户体验
- 降低总存储成本
本应用场景案例参见 DBS(新加坡星展银行)。
应用场景3:”零拷贝”混合云迁移
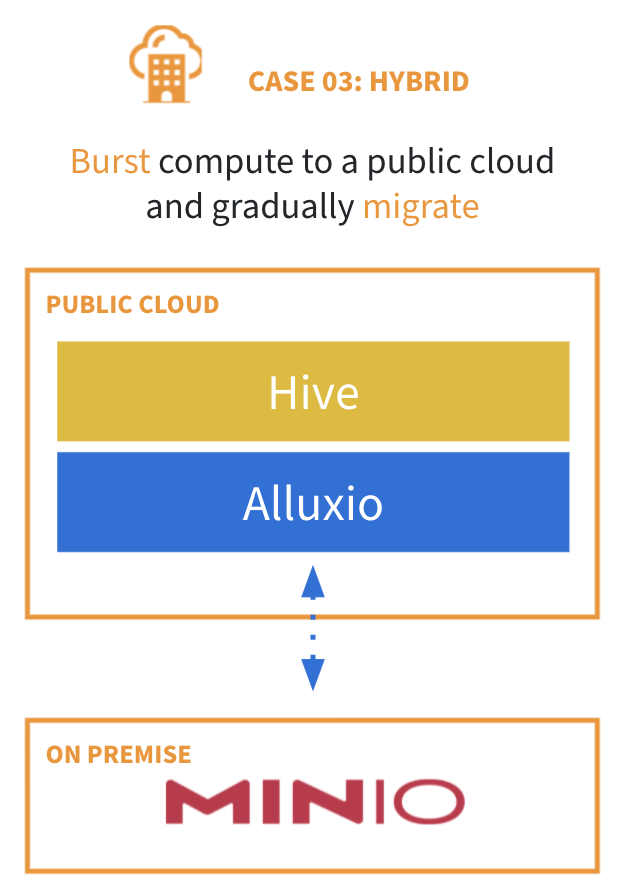
随着越来越多的企业迁移上云,其中一种常见的过渡做法是利用云上的计算资源,同时从本地数据源读取数据。但是,这种混合架构带来了下列问题:
- 远程读取数据速度慢且不稳定
- 将数据拷贝到云存储耗时,复杂且易出错
- 合规性和数据主权相关规定不允许将数据拷贝上云
Alluxio提供”零拷贝”上云功能,使得云上的计算引擎能够访问本地数据,而无需持久化的数据复制或定期同步。这一功能可带来以下益处:
- 性能等同于数据位于云计算集群上
- 不影响终端用户体验和安全模式
- 普通数据访问层采用基于访问和策略的数据移动
- 可利用弹性云计算资源,降低成本
本应用场景案例参见 Walmart(沃尔玛)。
应用场景4:云上数据的混合云存储网关
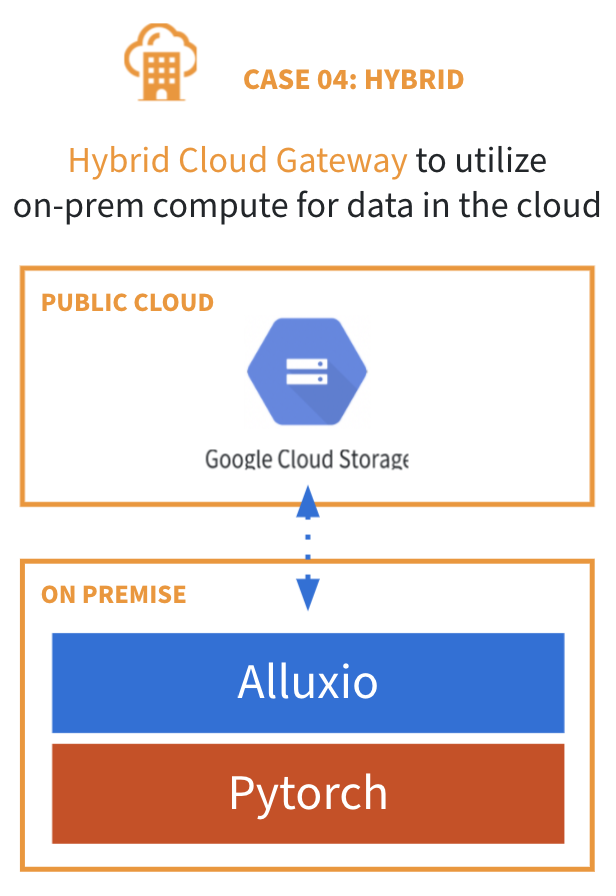
另一种混合云架构是从私有数据中心访问云存储。使用这种架构通常会导致以下问题:
- 没有云存储和本地存储的统一视图
- 网络流量成本过高
- 无法使用本地计算引擎访问云上数据
- 运行分析和AI作业时性能不佳
Alluxio 作为混合云存储网关,可利用本地计算处理云上数据, 从而解决这些问题。当Alluxio与本地计算一同部署时,Alluxio可管理计算集群的存储并将应用所需数据本地化,从而实现:
- 通过智能分布式缓存提高读写性能
- 减少数据复制,从而节约网络成本
- 提供灵活API接口和云存储安全模式,不影响终端用户体验
本应用场景案例参见 Comcast(康卡斯特)。
应用场景5:支持跨数据中心的数据访问
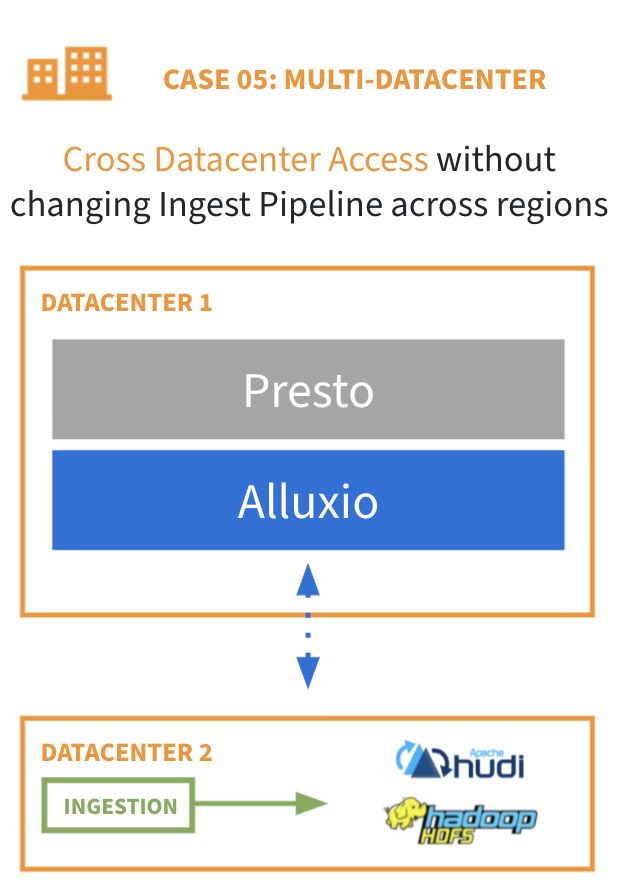
许多企业出于性能、安全或资源隔离的目的,建立了独立于主数据集群的卫星计算集群。由于这些卫星集群需要通过主集群远程访问数据,有一定难度,这是因为:
- 跨数据中心的副本需要手动操作,非常耗时
- 数据拷贝导致不必要的高昂网络成本
- 在过载的存储集群上进行复制作业严重影响现有负载的性能
Alluxio 可以作为一个数据逻辑副本,部署在卫星集群中的计算节点上,并配置为连接到主数据集群,因此:
- 无需跨数据中心维护冗余的副本
- 减少复杂的数据同步
- 与远程访问数据相比实现性能提升
- 实现跨业务部门的自主数据架构