
概览
![]()

欢迎使用Alluxio文档!在这里,您将找到有关部署Alluxio,Alluxio与各种技术栈集成,API参考等资源。如果您有任何问题期待交流,请加入Alluxio Slack社区 alluxio.io/slack。
Alluxio Enterprise AI 概述
Alluxio Enterprise AI 作为高性能的数据平台,他通过分布式的软件架构和智能缓存显著增强机器学习训练和数据访问的能力。它增强了数据在计算侧的访问效率,给客户提供了一种高性能并且易于运维的解决方案去访问EB数据量百亿文件以上的数据湖。我们的平台重新定义了AI训练和推理访问数据的方式,无论数据位于处于云上或者数据中心,用户可以高效的利用所有数据来支持机器学习平台的模型训练与模型上线业务。
卓越的性能
模型训练: 利用专为 AI 工作负载定制的高性能低延迟的分布式缓存,在数据湖之上可实现高达 20 倍的 I/O 性能。Alluxio 可在训练工作流程的各个阶段提高读取数据集到写入模型的 IO 性能,从而消除 GPU 因IO缓慢造成的性能瓶颈。 模型服务: 与直接从对象存储提供模型服务相比,通过Alluxio从离线训练集群向离线和在线推理节点提供模型上线的速度最高可达对象存储的 10 倍以上。Alluxio完全分布式的缓存架构可轻松扩展到为数千个推理节点提供服务,让你无需担心模型更新的高延迟。
无缝数据访问
使用 Kubernetes 在 GPU 集群上快速部署 Alluxio,并将Alluxio与存储集群连接。无需迁移数据,即可以开启高性能的训练作业,并最大限度地缩短机器学习平台在不同云和本地集群上的生产时间。
高可扩展性
我们的分布式系统架构能够在云上使用通用硬件低延迟地访问超过1000亿对象。
成本效益
Alluxio 解决方案不需要额外购买专用存储硬件即可提高性能。它可以与现有的数据湖和存储解决方案无缝集成,将Alluxio与GPU集群部署在一起,以高 I/O 吞吐量为GPU集群提供高性能的数据访问服务。
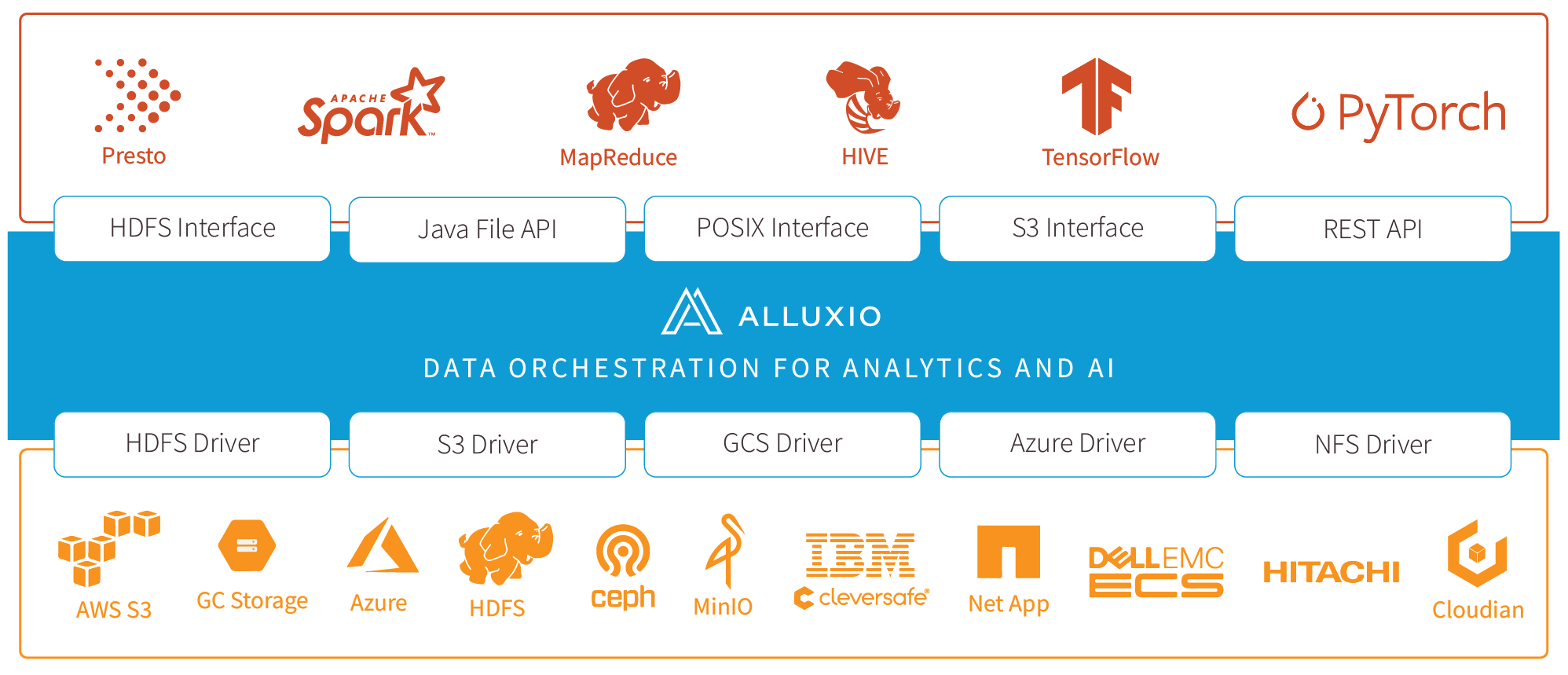
与AI框架集成
Alluxio Enterprise AI 支持各种主流的IO接口,包括 POSIX(基于 FUSE)、S3 和 FSSpec,可无缝对接 PyTorch、TensorFlow、Apache Ray 或 Spark 等主流框架。 Alluxio Enterprise AI 是一个完整的解决方案,旨在满足现代人工智能和 ML 工作负载的IO需求。它具有卓越的性能、无缝的数据访问能力和可扩展性,是企业高效扩展人工智能业务的必备工具。
通过Kubernetes Operator部署
请参阅 在 Kubernetes 上安装 Alluxio 的文档, 了解如何通过 Helm(Kubernetes 包管理器)和 Operator (用于管理应用程序的 Kubernetes 扩展) 在 Kubernetes 上安装 Alluxio。