
文件分片
![]()

文件分片介绍
Alluxio 中的每个文件都有自己唯一的文件 ID。
文件 ID 是 Worker 选择算法的关键,该算法决定哪个 Worker 负责缓存该文件的元数据和数据。 Client 端实现了同样的算法,因此 client 知道应该访问哪个 Worker 来获取缓存的文件。 无论文件的大小如何,worker 都会缓存整个文件。 在读取文件时,无论是要读取文件的哪个部分,Client 都会访问同一个 Worker。
当与 worker 的缓存存储容量相比,存储在 Alluxio 中的文件属于中小型文件时,该方案运行良好。 单个 worker 可以轻松地处理大量此类不大的文件,并且 worker 选择算法会将文件大致均匀地分配到不同的 worker 上。 但是,如果文件非常大,其大小与单个 Worker 的缓存容量相当,则有效地缓存这些巨大的文件会变得越来越困难。 如果多个 client 请求读取相同的文件,该 worker 就容易过载,从而影响整体读取性能。
文件分片是 Alluxio 的一项功能,它允许在多个 Worker 上以多个分片的方式缓存大文件。 分片的大小可由管理员配置,通常比文件大小要小得多。 分片文件可由多个 worker 高效处理,从而降低 worker 负载失衡的风险。
文件分片适用于以下场景:
- 在 Alluxio 缓存中存储超大文件,文件大于或接近一个 worker 的缓存容量
- 要求高读取性能的应用程序,可以通过多个 worker 处理同一个文件来提升性能
文件分片工作原理
如果将文件看作是一个由分片组成的有序列表,则文件的分片就可以定义为文件的 ID 及其在文件中的索引:
>
分片的 ID 定义为包含文件 ID 和分片索引的元组:
Segment ID := (fileId, segmentIndex)
当 client 需要定位一个分片文件的多个部分时, 分片 ID 将取代文件 ID 成为 worker 选择算法的关键。 分片文件的读取可拆分为按顺序分片读取。 下面是一个由 4 个分片组成的文件示例:
>
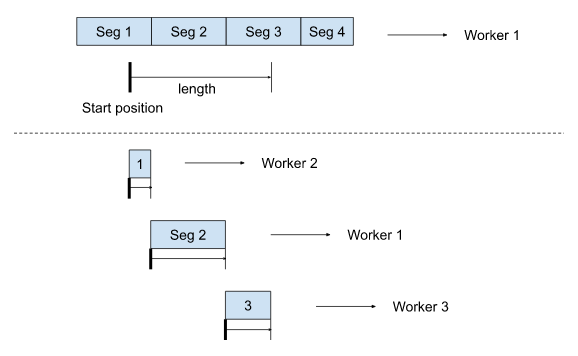
跨3个分片区域的连续读取可被拆分成对 3 个分片的读取,每个分片将由不同的 worker 处理。
文件分片的局限性
目前,文件分片存在一些局限性:
- 由 client 直接在 Alluxio 中创建和写入的文件无法进行分片
- 分片大小在整个集群范围内设置,所有节点必须共享相同的分片大小,不能按文件单独设置。
启用文件分片
| 配置项 | 推荐值 | 描述 |
|---|---|---|
alluxio.dora.file.segment.read.enabled |
true | 设置为 true 来启用文件分片功能 |
alluxio.dora.file.segment.size |
(由具体使用场景决定) | 分片大小,默认为1 GB |
在 Alluxio 的所有节点(包括 client )上将 alluxio.dora.file.segment.read.enabled 设置为 true。
将alluxio.dora.file.segment.size设置为所需的分片大小;此值也应在所有节点上保持一致。
最佳分片大小可通过以下因素来确定:
- 不同的分片可能会映射到不同的 worker 上。 在顺序读取文件时,client 需要在不同 worker 之间切换,来读取不同的分片。 如果分片的大小太小,client 就不得不频繁地在不同 worker 之间切换,从而导致网络带宽利用不足。
- 一个分片的数据完整地存储在一个 worker 中。 如果分片过大,不同 worker 上缓存使用不均的几率就会增加。
最佳分片大小是在性能和缓存数据均匀分布两者间的权衡。 分片大小的范围一般在几 GB 到几十 GB 之间。