

Caching
![]()

- Alluxio Storage Overview
- Configuring Alluxio Storage
- Managing the Data Lifecycle in Alluxio
- Managing Data Replication in Alluxio
- Checking Alluxio Cache Capacity and Usage
Alluxio Storage Overview
The purpose of this documentation is to introduce users to the concepts behind Alluxio storage and the operations that can be performed within Alluxio storage space. For metadata related operations such as syncing and namespaces, refer to the page on namespace management
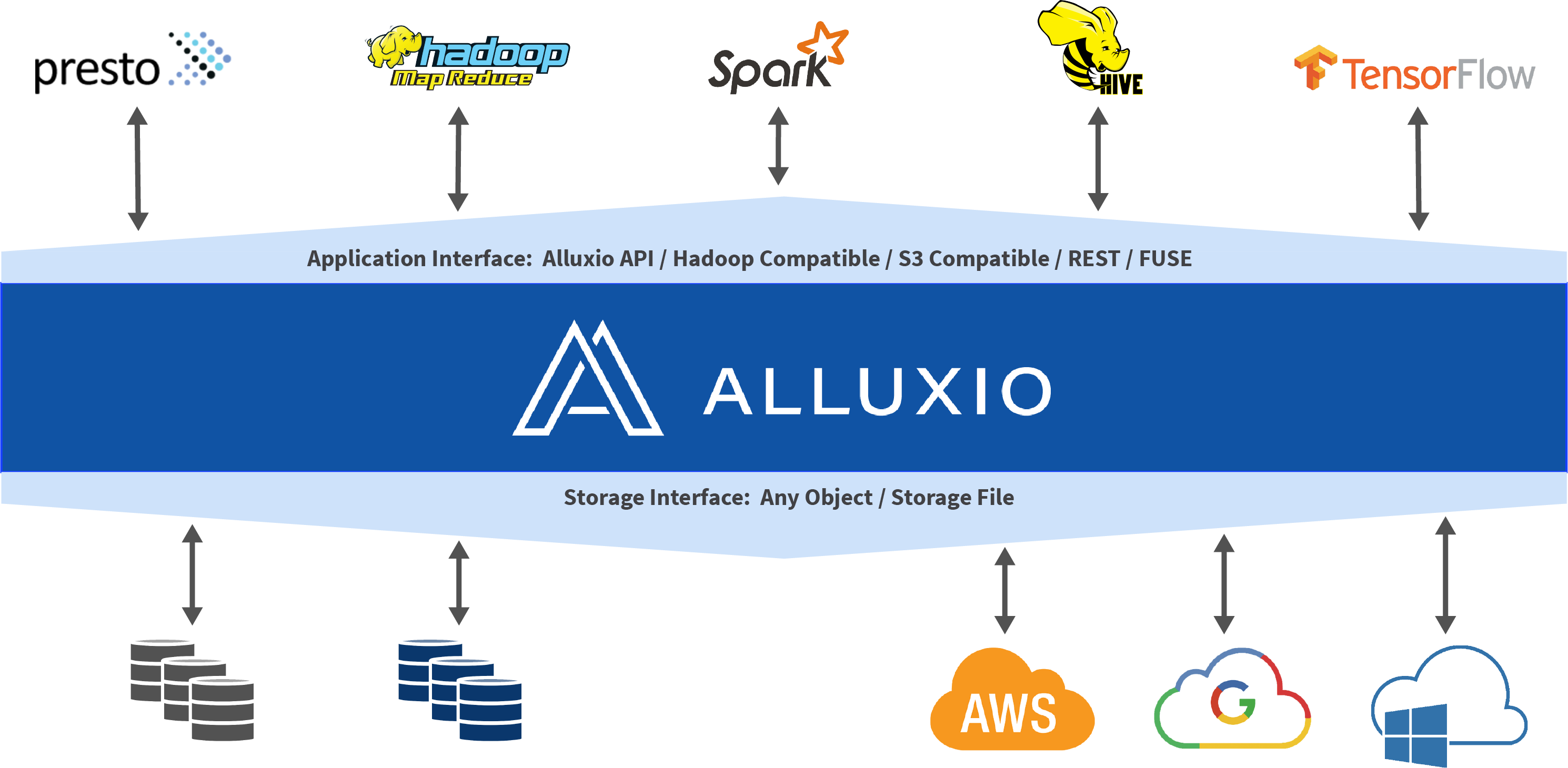
Alluxio helps unify users’ data across a variety of platforms while also helping to increase overall I/O throughput. Alluxio accomplishes this by splitting storage into two distinct categories.
- UFS (Under File Storage, also referred to as under storage)
- This type of storage is represented as space which is not managed by Alluxio. UFS storage may come from an external file system, including HDFS or S3. Alluxio may connect to one or more of these UFSs and expose them within a single namespace.
- Typically, UFS storage is aimed at storing large amounts of data persistently for extended periods of time.
- Alluxio storage
- Alluxio manages the local storage, including memory, of Alluxio workers to act as a distributed buffer cache. This fast data layer between user applications and the various under storages results in vastly improved I/O performance.
- Alluxio storage is mainly aimed at storing hot, transient data and is not focused on long term persistence.
- The amount and type of storage for each Alluxio worker node to manage is determined by user configuration.
- Even if data is not currently within Alluxio storage, files within a connected UFS are still visible to Alluxio clients. The data is copied into Alluxio storage when a client attempts to read a file that is only available from a UFS.
Alluxio storage improves performance by storing data in memory co-located with compute nodes. Data in Alluxio storage can be replicated to make “hot” data more readily available for I/O operations to consume in parallel.
Replicas of data within Alluxio are independent of the replicas that may exist within a UFS. The number of data replicas within Alluxio storage is determined dynamically by cluster activity. Due to the fact that Alluxio relies on the under file storage for a majority of data storage, Alluxio does not need to keep copies of data that are not being used.
Alluxio also supports tiered storage configurations such as memory, SSD, and HDD tiers which can make the storage system media aware. This enables decreased fetching latencies similar to how L1/L2 CPU caches operate.
Configuring Alluxio Storage
Single-Tier Storage
The easiest way to configure Alluxio storage is to use the default single-tier mode.
Note that this page refers to local storage and terms like mount refer to mounting in the local
filesystem, not to be confused with Alluxio’s mount concept for external under storages.
On startup, Alluxio will provision a ramdisk on every worker and take a percentage of the system’s total memory. This ramdisk will be used as the only storage medium allocated to each Alluxio worker.
Alluxio storage is configured through Alluxio’s configuration in alluxio-site.properties. See
configuration settings for detailed
information.
A common modification to the default is to set the ramdisk size explicitly. For example, to set the ramdisk size to be 16GB on each worker:
alluxio.worker.ramdisk.size=16GB
Another common change is to specify multiple forms of storage media, such as ramdisk and SSDs within
the same tier.
To do this, update alluxio.worker.tieredstore.level0.dirs.{path/mediumtype} specifying each storage path desired, and its particular medium.
For example, to use the ramdisk (mounted at /mnt/ramdisk) and two SSDs (mounted at /mnt/ssd1 and /mnt/ssd2):
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk,/mnt/ssd1,/mnt/ssd2
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM,SSD,SSD
Note that the ordering of the medium types must match the ordering of the paths.
Here, MEM and SSD are two preconfigured types in Alluxio.
alluxio.master.tieredstore.global.mediumtype is a configuration parameter that has a list of
all available medium types and by default it is set to MEM, SSD, HDD.
This list can be modified if the user has additional storage media types.
The paths provided should point to paths in the local filesystem which are mounted to the
appropriate storage media.
To enable short circuit operations, the permissions of these paths should be permissive for the
client user to read, write, and execute on the path.
For example, 770 permissions are needed for the client user who is among the same group of the
user that starts the Alluxio service.
After updating the storage media, we need to indicate how much storage is allocated for each storage directory. For example, if we wanted to use 16 GB on the ramdisk and 100 GB on each SSD:
alluxio.worker.tieredstore.level0.dirs.quota=16GB,100GB,100GB
Note that the ordering of the quotas must match the ordering of the paths.
Alluxio will provision and mount a ramdisk when started with the Mount or SudoMount options.
This ramdisk will have its size determined by alluxio.worker.ramdisk.size
In the default case where tier 0 is MEM and is allocated the entire ramdisk,
alluxio.worker.tieredstore.level0.dirs.quota has the same value as
alluxio.worker.ramdisk.size.
However, if tier 0 is not MEM or if it is not allocated the entire space of the ramdisk,
alluxio.worker.tieredstore.level0.dirs.quota should be configured explicitly to indicate
the amount allocated for tier 0.
Multiple-Tier Storage
It is typically recommended to use a single storage tier with heterogeneous storage media. In certain environments, workloads will benefit from the explicit ordering of storage media based on I/O speed. Alluxio assumes that tiers are ordered from top to bottom based on I/O performance. For example, users often specify the following tiers:
- MEM (Memory)
- SSD (Solid State Drives)
- HDD (Hard Disk Drives)
Writing Data
When a user writes a new block, it is written to the top tier by default. If the top tier does not have enough free space, then the next tier is tried. If no space is found on all tiers, Alluxio frees up space for new data as its storage is designed to be volatile. Eviction will start attempting to evict blocks from the worker, based on the block annotation policies. If eviction cannot free up new space, then the write will fail.
Note: Alluxio’s eviction model is synchronous and is executed when a client requires free space when writing a block.
alluxio.worker.tieredstore.free.ahead.bytes(Default: 0) can be configured to free up more bytes than necessary per eviction attempt
to reduce the number of evictions triggered. This changed starting in Alluxio 2.3.0 which decommissioned the old watermark-based eviction process.
The user can also specify the tier that the data will be written to via configuration settings.
Reading Data
If the data is already in Alluxio, the client will simply read the block from where it is already stored.
If Alluxio is configured with multiple tiers, the block may not be necessarily read from the top tier,
since it may have been loaded into a lower tier, or moved to a lower tier transparently.
This logic applies to both ReadType.CACHE and ReadType.CACHE_PROMOTE.
The difference is, reading data with ReadType.CACHE_PROMOTE will attempt to first transfer the block to the
top tier before it is read from the worker. This can also be used as a data management strategy by
explicitly moving hot data to higher tiers.
For ReadType.CACHE, Alluxio will cache the block into the highest tier that has the available space.
So you will read the cache block with disk speed if the block is currently on a disk(SSD/HDD).
Note: In 2.3, Alluxio default ReadType was changed from
CACHE_PROMOTEtoCACHE. This is because moving the block to the top tier synchronously during a read will cause delays. In 2.3, we changedCACHEto utilize tiered storage management tasks to maintain block ordering asynchronously across tiers. Blocks are now promoted according to the annotator policy.
Configuring Tiered Storage
Tiered storage can be enabled in Alluxio using configuration parameters. To specify additional tiers for Alluxio, use the following configuration parameters:
alluxio.worker.tieredstore.levels
alluxio.worker.tieredstore.level{x}.alias
alluxio.worker.tieredstore.level{x}.dirs.quota
alluxio.worker.tieredstore.level{x}.dirs.path
alluxio.worker.tieredstore.level{x}.dirs.mediumtype
For example, if you wanted to configure Alluxio to have two tiers, memory and hard disk drive, you could use a configuration similar to:
# configure 2 tiers in Alluxio
alluxio.worker.tieredstore.levels=2
# the first (top) tier to be a memory tier
alluxio.worker.tieredstore.level0.alias=MEM
# defined `/mnt/ramdisk` to be the file path to the first tier
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
# defined MEM to be the medium type of the ramdisk directory
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM
# set the quota for the ramdisk to be `100GB`
alluxio.worker.tieredstore.level0.dirs.quota=100GB
# configure the second tier to be a hard disk tier
alluxio.worker.tieredstore.level1.alias=HDD
# configured 3 separate file paths for the second tier
alluxio.worker.tieredstore.level1.dirs.path=/mnt/hdd1,/mnt/hdd2,/mnt/hdd3
# defined HDD to be the medium type of the second tier
alluxio.worker.tieredstore.level1.dirs.mediumtype=HDD,HDD,HDD
# define the quota for each of the 3 file paths of the second tier
alluxio.worker.tieredstore.level1.dirs.quota=2TB,5TB,500GB
There are no restrictions on how many tiers can be configured but each tier must be identified with a unique alias.
For each tier, the following parameters are available:
alluxio.worker.tieredstore.level{x}.dirs.path: comma-separated list of directories for that tier. Example:/mnt/hdd1,/mnt/hdd2,/mnt/hdd3alluxio.worker.tieredstore.level{x}.dirs.quota: comma-separated list of the quotas of the corresponding directories specified inalluxio.worker.tieredstore.level{x}.dirs.path. Example:2TB,5TB,500GBalluxio.worker.tieredstore.level{x}.dirs.mediumtype: comma-separated list of the medium types of the corresponding directories specified inalluxio.worker.tieredstore.level{x}.dirs.path. Example:HDD,HDD,HDD
A typical configuration will have three tiers for Memory, SSD, and HDD.
To use multiple hard drives in the HDD tier, specify multiple paths when configuring
alluxio.worker.tieredstore.level{x}.dirs.path.
Block Allocation Policies
Alluxio uses block allocation policies to define how to allocate new blocks across multiple storage directories (in the same tier or across different tiers). The allocation policy defines which storage directory to allocate the new block in.
This is configured by worker property alluxio.worker.allocator.class. Out-of-the-box implementations include:
-
MaxFreeAllocator: Start trying from tier 0 to the lowest tier, and try to allocate the block to the storage directory that currently has the most availability. This is the default behavior.
-
RoundRobinAllocator: Start trying from tier 0 to the lowest tier. On each tier, maintain a Round Robin order of storage directories. Try to allocate the new block into a directory following the Round Robin order, and if that does not work, go to the next lower tier.
-
GreedyAllocator: This is an example implementation of the
Allocatorinterface. It loops from the top tier to the lowest tier, trying to put the new block into the first directory that can contain the block.
[Experimental] Block Allocation Review Policies
This is an experimental feature added in Alluxio 2.4.1. The interface is subject to change in future versions.
Alluxio uses block allocation review policies to complement allocation policies. In comparison to allocation policies
which define what the allocation should be, the allocation review process validates allocation decisions and prevent
the ones that are not good enough. The Reviewer works together with the Allocator
This is configured by worker property alluxio.worker.reviewer.class. Out-of-the-box implementations include:
-
ProbabilisticBufferReviewer: Based on the available space in each storage directory, rejects the attempts to put new blocks into this directory probabilistically. The probability is determined by
alluxio.worker.reviewer.probabilistic.hardlimit.bytesandalluxio.worker.reviewer.probabilistic.softlimit.bytes. When the available space in the directory is underalluxio.worker.reviewer.probabilistic.hardlimit.bytes, which is64MBby default, new blocks will be rejected. When the available space in the directory is abovealluxio.worker.reviewer.probabilistic.softlimit.bytes, which is256MBby default, new blocks will NOT be rejected. When the available space is between these two values, the probability of accepting a new block goes down linearly to as the availability goes down. We choose to reject new blocks early before a directory is filled up, because the existing blocks in the directory can expand in size as we read new data in the block. Leaving a buffer in each directory can reduce the chance of eviction. This is the default behavior. -
AcceptingReviewer: This reviewer accepts every block allocation. So the behavior will be exactly the same as Alluxio before 2.4.1.
Block Annotation Policies
Alluxio uses block annotation policies, starting in 2.3.0, to maintain strict ordering of blocks in storage.
Annotation policies define an ordering for blocks across tiers and is consulted during:
- Eviction
- Dynamic Block Placement
The eviction, that happens during writes, will attempt to remove blocks based on the order enforced by the block annotation policy. The last block in annotated order is the first candidate for eviction regardless of which tier it’s on.
Out-of-the-box annotation implementations include:
- LRUAnnotator: Annotates the blocks based on least-recently-used order. This is Alluxio’s default annotator.
- LRFUAnnotator: Annotates the blocks based on least-recently-used and least-frequently-used orders with a
configurable weight.
- If the weight is completely biased toward least-recently-used, the behavior will be the same as the LRUAnnotator.
- The applicable configuration properties are
alluxio.worker.block.annotator.lrfu.step.factorandalluxio.worker.block.annotator.lrfu.attenuation.factor.
The annotator utilized by workers is determined by the Alluxio property
alluxio.worker.block.annotator.class.
The property should specify the fully qualified class name within the configuration.
Currently, the available options are:
alluxio.worker.block.annotator.LRUAnnotatoralluxio.worker.block.annotator.LRFUAnnotator
Evictor Emulation
The old eviction policies are now removed and Alluxio provided implementations are replaced with appropriate annotation policies.
Configuring old Alluxio evictors will cause worker startup failure with java.lang.ClassNotFoundException.
Also, the old watermark based configuration is no longer usable.
Using previous configuration options is ineffective:
alluxio.worker.tieredstore.levelX.watermark.low.ratioalluxio.worker.tieredstore.levelX.watermark.high.ratio
However, Alluxio supports an emulation mode which annotates blocks based on custom evictor implementations. The emulation assumes the configured eviction policy creates an eviction plan based on some kind of order and works by regularly extracting this order to be used in annotation activities.
The old evictor configurations should be changed as below. (Failing to change the left-over configuration will cause class load exceptions as old evictor implementations are removed.)
- LRUEvictor -> LRUAnnotator
- GreedyEvictor -> LRUAnnotator
- PartialLRUEvictor -> LRUAnnotator
- LRFUEvictor -> LRFUAnnotator
Tiered Storage Management
Block allocation/eviction no longer enforces a particular tier for new writes. This means a freshly written blocks could end up in any configured tier. These newer changes allow writing data bigger than Alluxio storage capacity. However, it also requires Alluxio to dynamically manage block placement. To enforce the assumption that tiers are configured from fastest to slowest, Alluxio now moves blocks around tiers based on block annotation policies.
Below configuration is honored by each individual tier management task:
alluxio.worker.management.task.thread.count: How many threads to use for management tasks. (Default: the maximum value of4andCPU core count. Check the up-to-date reference.)alluxio.worker.management.block.transfer.concurrency.limit: How many block transfers can execute concurrently. (Default: the maximum value of2andCPU core count / 2. Check the up-to-date reference.)
Block Aligning (Dynamic Block Placement)
Alluxio will dynamically move blocks across tiers in order to achieve a block storage composition that is in line with the configured block annotation policy.
To compensate for this, Alluxio watches I/O patterns and reorganizes blocks across tiers to make sure the lowest block of a higher tier has higher order than the highest block of a tier below.
This is achieved by align management task. This task, upon detecting blocks within tiers being out
of order, swaps the out-of-order blocks among tiers to eliminate misordering among blocks and
effectively align the tiers to the configured annotation policy.
See the Management Task Back-Off section for how to control the effect
of these new background tasks alongside user I/O.
To control tier aligning:
alluxio.worker.management.tier.align.enabled: Whether tier aligning task is enabled. (Default:true)alluxio.worker.management.tier.align.range: How many blocks to align in a single task run. (Default:100)alluxio.worker.management.tier.align.reserved.bytes: The amount of space to reserve on all directories by default when multiple tiers are configured. (Default:1GB) This is used for internal block movements.alluxio.worker.management.tier.swap.restore.enabled: This controls a special task that is used to unblock tier alignment when internal reserved space is exhausted. (Default:true) Reserved space can be exhausted due to the fact that Alluxio supports variable block sizes, so swapping blocks between tiers during aligning can decrease reserved space on a directory when block sizes don’t match.
Block Promotions
When a higher tier has free space, blocks from a lower tier are moved up in order to better utilize faster disks as it’s assumed the higher tiers are configured with faster disks.
To control dynamic tier promotion:
alluxio.worker.management.tier.promote.enabled: Whether tier promotion task is enabled. (Default:true)alluxio.worker.management.tier.promote.range: How many blocks to promote in a single task run. (Default:100)alluxio.worker.management.tier.promote.quota.percent: The max percentage of each tier that could be used for promotions. Promotions will be stopped to a tier once its used space goes over this value. (0 means never promote, and, 100 means always promote.)
Management Task Back-Off
Tier management tasks (align/promote) are respectful to user I/O and back off whenever a worker or disk is under load. This behavior is to make sure Alluxio storage management doesn’t negatively impact user I/O performance.
There are two back-off types available, ANY and DIRECTORY, that can be set in the
alluxio.worker.management.backoff.strategy property.
-
ANY; management tasks will back off from the worker when there is any user I/O. This mode will ensure low management task overhead in order to favor immediate user I/O performance. However, making progress on management tasks will require quiet periods on the worker. -
DIRECTORY; management tasks will back off from directories with ongoing user I/O. This mode will give a better chance of making progress on management tasks However, immediate user I/O throughput might be decreased due to increased management task activity.
An additional property that effects both back-off strategies is
alluxio.worker.management.load.detection.cool.down.time that controls how long user I/O will be
counted as a load on target directory/worker.
[Experimental] Paging Worker Storage
This is an experimental feature added in Alluxio 2.8.2/2.9.0.
Alluxio supports finer-grained page-level (typically, 1 MB) caching storage on Alluxio workers, as an alternative option to the existing block-based (defaults to 64 MB) tiered caching storage. This paging storage supports general workloads including reading and writing, with customizable cache eviction policies similar to block annotation policies in tiered block store.
To switch to the paging storage:
alluxio.worker.block.store.type=PAGE
You can specify multiple directories to be used as cache storage for the paging store.
For example, to use two SSDs (mounted at /mnt/ssd1 and /mnt/ssd2):
alluxio.worker.page.store.dirs=/mnt/ssd1,/mnt/ssd2
You can set a limit to the maximum amount of storage for cache for each of the directories. For example, to allocate 100 GB of space on each SSD:
alluxio.worker.page.store.sizes=100GB,100GB
Note that the ordering of the sizes must match the ordering of the dirs. It is highly recommended to allocate all directories to be the same size, since the allocator will distribute data evenly.
To specify the page size:
alluxio.worker.page.store.page.size=1MB
A larger page size might improve sequential read performance, but it may take up more cache space. We recommend to use the default value (1MB) for Presto workload (reading Parquet or Orc files).
To enable the asynchronous writes for paging store:
alluxio.worker.page.store.async.write.enabled=true
You might find this property helpful if you notice performance degradation when there are a lot of cache misses.
Managing the Data Lifecycle in Alluxio
Users should understand the following concepts to utilize available resources properly:
- free: Freeing data means removing data from the Alluxio cache, but not the underlying UFS. Data is still available to users after a free operation, but performance may be degraded for clients who attempt to access a file after it has been freed from Alluxio.
- load: Loading data means copying it from a UFS into Alluxio cache. If Alluxio is using memory-based storage, users will likely see I/O performance improvements after loading.
- persist: Persisting data means writing data which may or may not have been modified within Alluxio storage back to a UFS. By writing data back to a UFS, data is guaranteed to be recoverable if an Alluxio node goes down.
- TTL (Time to Live): The TTL property sets an expiration duration on files and directories to remove them from Alluxio space when the data exceeds its lifetime. It is also possible to configure TTL to remove the corresponding data stored in a UFS.
Freeing Data from Alluxio Storage
In order to manually free data in Alluxio, you can use the ./bin/alluxio file system command
line interface.
$ ./bin/alluxio fs free ${PATH_TO_UNUSED_DATA}
This will remove the data at the given path from Alluxio storage. The data is still accessible if it is persisted to a UFS. For more information refer to the command line interface documentation
Note that a user typically should not need to manually free data from Alluxio as the configured annotation policy will take care of removing unused or old data.
Loading Data into Alluxio Storage
If the data is already in a UFS, use
alluxio fs load
$ ./bin/alluxio fs load ${PATH_TO_FILE}
To speed up the loading process for files or directories, use the distributedLoad command instead of load command.
To load data from the local file system, use the command
alluxio fs copyFromLocal.
This will only load the file into Alluxio storage, but may not persist the data to a UFS.
Setting the write type to MUST_CACHE write type will not persist data to a UFS,
whereas CACHE and CACHE_THROUGH will. Manually loading data is not recommended as Alluxio
will automatically load data into the Alluxio cache when a file is used for the first time.
Persisting Data in Alluxio
The command alluxio fs persist
allows a user to push data from the Alluxio cache to a UFS.
$ ./bin/alluxio fs persist ${PATH_TO_FILE}
This command is useful if you have data that you loaded into Alluxio which did not originate from a configured UFS. Users should not need to worry about manually persisting data in most cases.
Setting Time to Live (TTL)
Alluxio supports a Time to Live (TTL) setting on each file and directory in its namespace. This
feature can be used to effectively manage the Alluxio cache, especially in environments with strict
guarantees on the data access patterns. For example, if analytics is run on the last week of
ingested data, the TTL feature can be used to explicitly flush old data to free the cache for new
files.
Alluxio has TTL attributes associated with each file or directory. These attributes are saved as part of the journal and persist across cluster restarts. The active master node is responsible for holding the metadata in memory when Alluxio is serving requests. Internally, the master runs a background thread that periodically checks if files have reached their TTL expiration.
Note that the background thread runs on a configurable period, which is set to an hour by default. Data that has reached its TTL expiration immediately after a check will not be removed until the next check interval an hour later.
To set the interval to 10 minutes, add the following to alluxio-site.properties:
alluxio.master.ttl.checker.interval=10m
Refer to the configuration page for more details on setting Alluxio configurations.
APIs
There are two ways to set the TTL attributes of a path.
- Through the Alluxio shell command line
- Passively on each load metadata or create file
The TTL API is as follows:
SetTTL(path, duration, action)
path the path in the Alluxio namespace
duration the number of milliseconds before the TTL action goes into effect, this overrides
any previous value
action the action to take when the duration has elapsed. `FREE` will cause the file to be
evicted from Alluxio storage, regardless of the pin status. `DELETE` will cause the
file to be deleted from the Alluxio namespace and under store.
NOTE: `DELETE` is the default for certain commands and will cause the file to be
permanently removed.
Command Line Usage
See the detailed
command line documentation
to see how to use the setTtl command within the Alluxio shell to modify TTL attribute.
Passive TTL on files in Alluxio
The Alluxio client can be configured to add TTL attributes whenever it adds a new file to the Alluxio namespace. Passive TTL is useful in cases where files accessed by the user are expected to be temporarily used, but it is not flexible because all requests from the same client will inherit the same TTL attributes.
Passive TTL works with the following configuration options:
alluxio.user.file.create.ttl- The TTL duration to set on files in Alluxio. By default, no TTL duration is set.alluxio.user.file.create.ttl.action- The TTL action to set on files in Alluxio.NOTE: By default, this action is
DELETE.DELETEwill cause the file to be permanently removed from Alluxio namespace and under store.
TTL is disabled by default and should only be enabled by clients which have strict data access patterns.
For example, to delete the files created by the runTests after 3 minutes:
$ ./bin/alluxio runTests -Dalluxio.user.file.create.ttl=3m \
-Dalluxio.user.file.create.ttl.action=DELETE
For this example, ensure the alluxio.master.ttl.checker.interval is set to a short
duration, such as a minute, in order for the master to quickly identify the expired files.
Managing Data Replication in Alluxio
Passive Replication
Like many distributed file systems, each file in Alluxio consists of one or multiple blocks stored
across the cluster. By default, Alluxio may adjust the replication level of different blocks
automatically based on the workload and storage capacity. For example, Alluxio may
create more replicas of a particular block when more clients request to read this block with read
type CACHE or CACHE_PROMOTE; Alluxio may also remove existing replicas when they are used less
often to reclaim the space for data that is accessed more often (Block Annotation Policies).
It is possible that in the same file different blocks have a different number
of replicas according to the popularity.
By default, this replication or eviction decision and the corresponding data transfer is completely transparent to users and applications accessing data stored in Alluxio.
Active Replication
In addition to the dynamic replication adjustment, Alluxio also provides APIs and command-line interfaces for users to explicitly maintain a target range of replication levels for a file explicitly. Particularly, a user can configure the following two properties for a file in Alluxio:
alluxio.user.file.replication.minis the minimum possible number of replicas of this file. Its default value is 0, so in the default case Alluxio may completely evict this file from Alluxio managed space after the file becomes cold. By setting this property to a positive integer, Alluxio will check the replication levels of all the blocks in this file periodically. When some blocks become under-replicated, Alluxio will not evict any of these blocks and actively create more replicas to restore the replication level.alluxio.user.file.replication.maxis the maximum number of replicas. Once the property of this file is set to a positive integer, Alluxio will check the replication level and remove the excessive replicas. Set this property to -1 to make no upper limit (the default case), and to 0 to prevent storing any data of this file in Alluxio. Note that, the value ofalluxio.user.file.replication.maxmust be no less thanalluxio.user.file.replication.min.
For example, users can copy a local file /path/to/file to Alluxio with at least two replicas initially:
$ ./bin/alluxio fs -Dalluxio.user.file.replication.min=2 \
copyFromLocal /path/to/file /file
Next, set the replication level range of /file between 3 and 5. Note that, this command will
return right after setting the new replication level range in a background process and achieving
the target asynchronously.
$ ./bin/alluxio fs setReplication --min 3 --max 5 /file
Set the alluxio.user.file.replication.max to unlimited.
$ ./bin/alluxio fs setReplication --max -1 /file
Recursively set replication level of all files inside a directory /dir (including its
sub-directories) using -R:
$ ./bin/alluxio fs setReplication --min 3 --max -5 -R /dir
To check the target replication level of a file, run
$ ./bin/alluxio fs stat /foo
and look for the replicationMin and replicationMax fields in the output.
Checking Alluxio Cache Capacity and Usage
The Alluxio shell command fsadmin report provides a short summary of space availability,
along with other useful information. A sample output is shown below:
$ ./bin/alluxio fsadmin report
Alluxio cluster summary:
Master Address: localhost/127.0.0.1:19998
Web Port: 19999
Rpc Port: 19998
Started: 09-28-2018 12:52:09:486
Uptime: 0 day(s), 0 hour(s), 0 minute(s), and 26 second(s)
Version: 2.0.0
Safe Mode: false
Zookeeper Enabled: false
Raft-based Journal: true
Raft Journal Addresses:
localhost:19200
localhost:19201
Live Workers: 1
Lost Workers: 0
Total Capacity: 10.67GB
Tier: MEM Size: 10.67GB
Used Capacity: 0B
Tier: MEM Size: 0B
Free Capacity: 10.67GB
The Alluxio shell also allows a user to check how much space is available and in use within the Alluxio cache.
To get the total used bytes in the Alluxio cache:
$ ./bin/alluxio fs getUsedBytes
To get the total capacity of the Alluxio cache in bytes:
$ ./bin/alluxio fs getCapacityBytes
The Alluxio master web interface gives the user a visual overview of the cluster and how much
storage space is used. It can be found at http:/{MASTER_IP}:${alluxio.master.web.port}/.
More detailed information about the Alluxio web interface can be
found in our documentation.