

Running Deep Learning Frameworks on Alluxio
![]()

With the age of growing datasets and increased computing power, deep learning has become a popular technique for AI. Deep learning models continue to improve their performance across a variety of domains, with access to more and more data, and the processing power to train larger neural networks. This rise of deep learning advances the state-of-the-art for AI, but also exposes some challenges for the access to data and storage systems. In this page, we further describe the storage challenges for deep learning workloads and show how Alluxio can help to solve them.
Data Challenges of Deep Learning
Deep learning has become popular for machine learning because of the availability of large amounts of data, where more data typically leads to better performance. However, there is no guarantee that all the training data are available to deep learning frameworks (Tensorflow, Caffe, torch). For example, deep learning frameworks have integrations with some existing storage systems, but not all storage integrations are available. Therefore, a subset of the data may be inaccessible for training, resulting in lower performance and effectiveness.
There is a variety of storage options for users, with distributed storage systems (HDFS, ceph) and cloud storage (AWS S3, Azure Blob Store, Google Cloud Storage) becoming popular. Practitioners who normally interact with a local file system are generally unfamiliar with these distributed and remote storage systems. It can be difficult to properly configure and use new and different tools for each storage system. This makes accessing data from diverse systems difficult for deep learning.
The growing trend of separating compute resources from storage resources necessitates using remote storage systems. This is common for cloud computing and enables on-demand resource allocation, which can lead to higher utilization, flexible elasticity, and lower costs. When remote storage systems are used for deep learning training data, their data must be fetched over the network, which can increase the training time for deep learning. The extra network I/O will increase costs and increase the time to process the data.
How Alluxio Helps Deep Learning Storage Challenges
While there are several data management related issues with deep learning, Alluxio can help with the challenge of accessing data. Alluxio in its simplest form is a virtual file system which transparently connects to existing storage systems and presents them as a single system to users. Using Alluxio’s unified namespace, many storage technologies can be mounted into Alluxio, including cloud storage like S3, Azure, and GCS. Because Alluxio can already integrate with storage systems, deep learning frameworks only need to interact with Alluxio to be able to access data from any connected storage. This opens the door for training to be performed on all data from any data source, which can lead to better model performance.
Alluxio also includes a FUSE interface for a convenient and familiar use experience. With Alluxio FUSE, an Alluxio instance can be mounted to the local file system, so interacting with Alluxio is as simple as interacting with local files and directories. This enables users to continue to use familiar tools and paradigms to interact with their data. Since Alluxio can connect to multiple disparate storages, data from any storage can be accessed like a local file or directory.
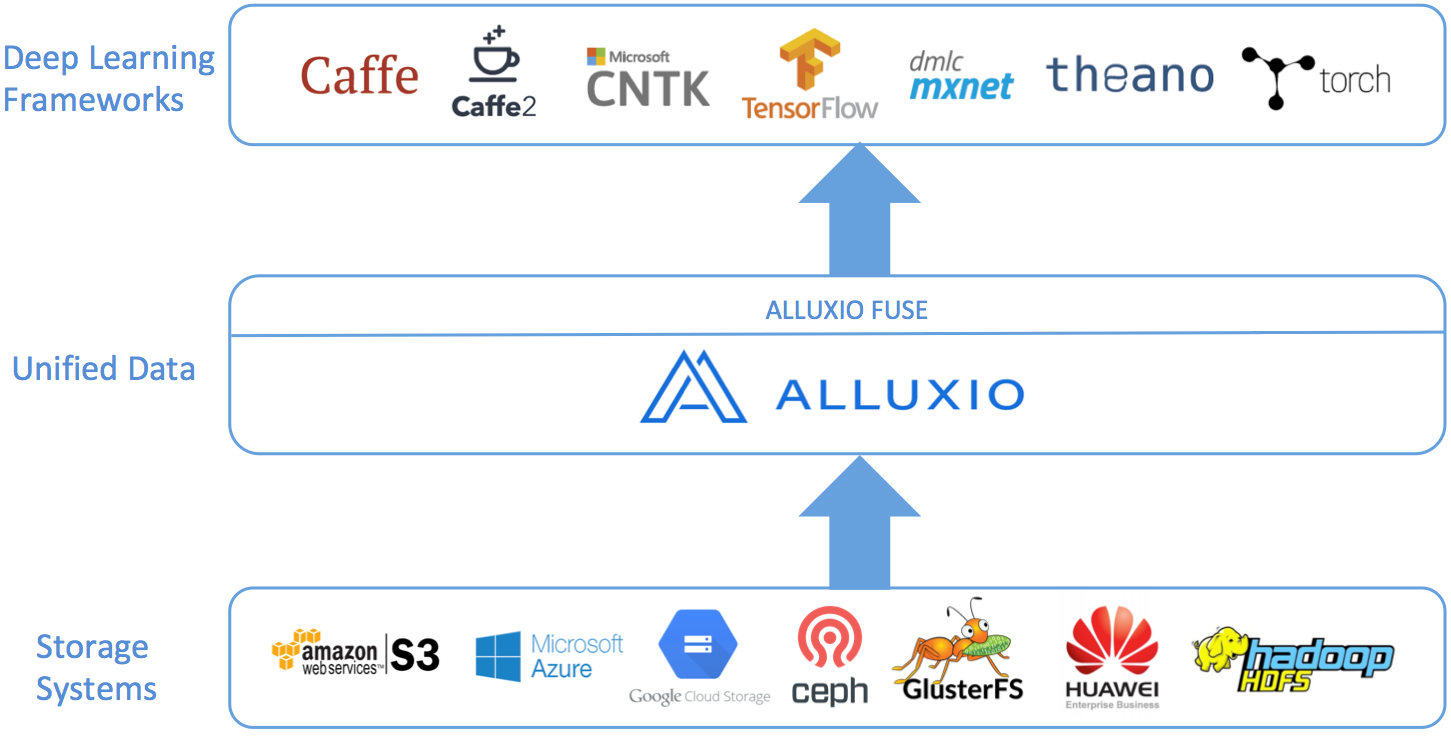
Alluxio also provides local caching of frequently used data. This is particularly useful when the data is remote from the computation. Since Alluxio can cache the data locally, network I/O is not incurred when accessing the data, so deep learning training can be more cost effective and take less time.