

Integrating CDH Compute with Alluxio
![]()

This guide describes how to configure Cloudera’s Distribution of Hadoop (CDH) compute frameworks to work with Alluxio.
Prerequisites
You should already have Cloudera’s Distribution installed. CDH 5 has been tested and the Cloudera Manager is used for the instructions in the rest of this document.
It is also assumed that Alluxio has been installed on the cluster.
Running CDH MapReduce
To run CDH MapReduce applications with Alluxio, some additional configuration is required.
Configuring core-site.xml
You need to add the following properties to core-site.xml. The ZooKeeper properties are only required for a cluster
using HA mode. Similarly, embedded journal properties are only required for an HA cluster using Embedded Journal.
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
<property>
<name>alluxio.zookeeper.enabled</name>
<value>true</value>
</property>
<property>
<name>alluxio.zookeeper.address</name>
<value>zknode1:2181,zknode2:2181,zknode3:2181</value>
</property>
<property>
<name>alluxio.master.embedded.journal.addresses</name>
<value>alluxiomaster1:19200,alluxiomaster2:19200,alluxiomaster3:19200</value>
</property>
To add configuration properties to core-site.xml with Cloudera Manager select the “HDFS” component in
Cloudera Manager, choose the “Configuration” and search for
“Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml”. This can be modified to add the
required properties. Refer to the picture below.
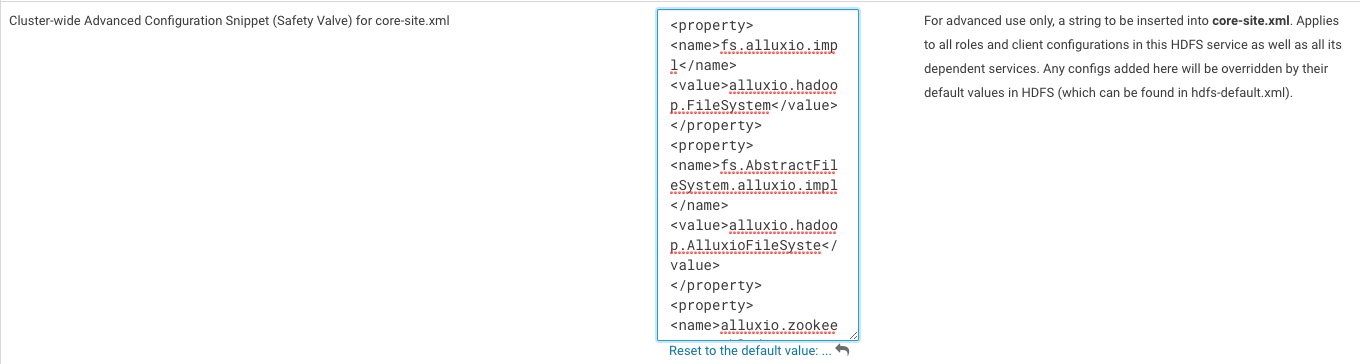
Then, save the configuration, and Cloudera Manager will notify you that you should deploy configurations and restart the affected components. Accept these options to continue.
Configuring HADOOP_CLASSPATH
In order for the Alluxio client jar to be available to the MapReduce applications, you must add
the Alluxio Hadoop client jar to the $HADOOP_CLASSPATH environment variable in hadoop-env.sh.
In the “YARN (MR2 Included)” section of the Cloudera Manager, in the “Configuration” tab, search for the parameter “Gateway Client Environment Advanced Configuration Snippet (Safety Valve) for hadoop-env.sh”. Then add the following line to the script:
HADOOP_CLASSPATH=/path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar:${HADOOP_CLASSPATH}
It should look something like this:

After saving the configuration, Cloudera Manager will notify you that the stale configuration files need to be redeployed and the affected components need to be restarted. Make sure to accept both options and restart the services. If using Alluxio with HDFS journaling, make sure that you stop Alluxio before rebooting HDFS.
Security
Since MapReduce runs on YARN, a non-secured Alluxio will need to be configured to allow the yarn user to impersonate
other users. To do this, add the below property to alluxio-site.properties on Alluxio Masters and Workers and then
restart the Alluxio cluster.
alluxio.master.security.impersonation.yarn.users=*
This is not required if Alluxio and YARN are Kerberized and Secured.
Running MapReduce Applications
In order for MapReduce applications to be able to read and write files in Alluxio, the Alluxio client jar must be distributed to all YARN nodes in the cluster and added to the application classpath.
Below are instructions for the 2 main alternatives for distributing the client jar.
Using the -libjars command line option
You can run a job by using the -libjars command line option when using yarn jar ...,
specifying
/path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar as the argument. This
will place the jar in the Hadoop DistributedCache, making it available to all the nodes. For
example, the following command adds the Alluxio client jar to the -libjars option:
$ yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar randomtextwriter -libjars /path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar <OUTPUT URI>
Setting the classpath configuration variables
If the Alluxio client jar is already distributed to all the nodes in the same path, you can add that jar to the
classpath using the mapreduce.application.classpath variable.
In the Cloudera Manager, you can find the mapreduce.application.classpath variable in the “YARN (MR2 Included)” component, in the “Configuration” tab. For the “MR Application Classpath”, add the Alluxio Hadoop client jar as a new entry.
/path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar
This will be added to the mapreduce.application.classpath parameter. It should look something like this:
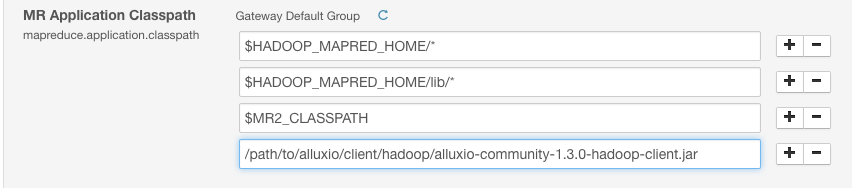
After you save the configuration, restart the affected components.
Running Sample MapReduce Application
In the following example, replace MASTER_HOSTNAME with your actual Alluxio master hostname.
$ yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar randomtextwriter -Dmapreduce.randomtextwriter.bytespermap=10000000 alluxio://MASTER_HOSTNAME:19998/testing/randomtext/
Note: You should make sure path
/testing/randomtextexists in Alluxio.
After this job completes, there will be randomly generated text files in the /testing/randomtext directory in Alluxio.
Running CDH Hive
Configuring HIVE_AUX_JARS_PATH
To run CDH Hive applications with Alluxio, additional configuration is required for the applications.
In the “Hive” section of the Cloudera Manager, in the “Configuration” tab, search for the parameter
“Hive Auxiliary JARs Directory”. Set it to /path/to/alluxio/client/, which is the directory containing
the Alluxio Client jar. This will effectively update HIVE_AUX_JARS_PATH parameter.
It should look something like this:
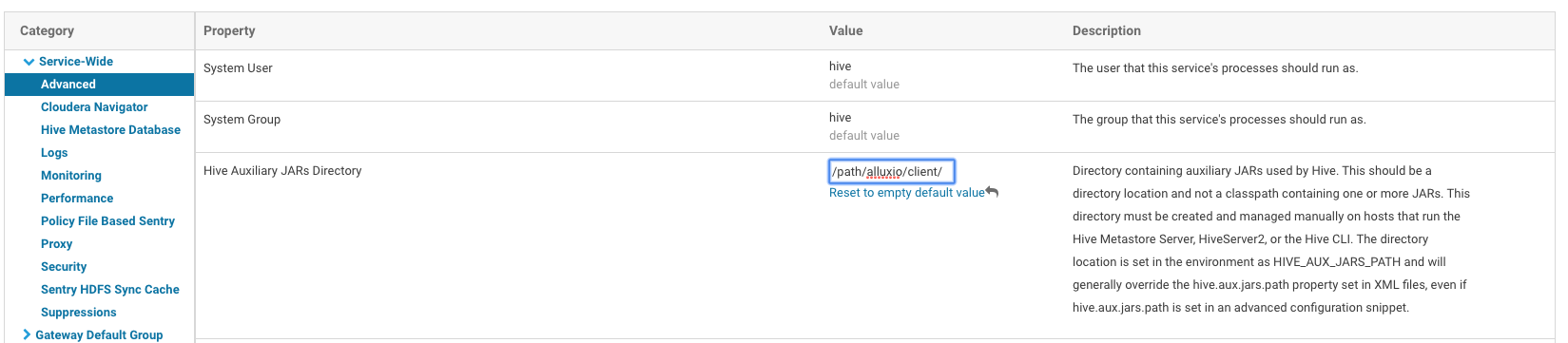
Then save the configuration, and the Cloudera Manager will notify you that you should deploy the configuration and restart the affected components. Please restart the affected components.
Security
For impersonation, Alluxio will need to be configured to allow the hive user to impersonate other users. To do this,
add the below property to alluxio-site.properties on Alluxio Masters and Workers and then restart the Alluxio cluster.
alluxio.master.security.impersonation.hive.users=*
Note: If
hive.doAsis disabled, this property is not required.
Create External Table Located in Alluxio
With the HIVE_AUX_JARS_PATH set, Hive can create external tables from files stored on Alluxio.
You can follow the sample Hive application on Running-Hive-on-Alluxio to create an
external table located in Alluxio.
(Optional) Use Alluxio as default file system
Hive can also use Alluxio through a generic file system interface to replace the Hadoop file system. In this way, the Hive uses Alluxio as the default file system and its internal metadata and intermediate results will be stored in Alluxio by default. To set Alluxio as the default file system for CDH Hive, in the “Hive” section of the Cloudera Manager, in the “Configuration” tab, search for the parameter “hive-site.xml”. The search result will contain “Hive Service Advanced Configuration Snippet (Safety Valve) for hive-site.xml” and “Hive Client Advanced Configuration Snippet (Safety Valve) for hive-site.xml”, please add the following property to both Hive Service and Hive Client hive-site.xml.
Name: fs.defaultFS
Value: alluxio://master_hostname:port
It should look something like this:
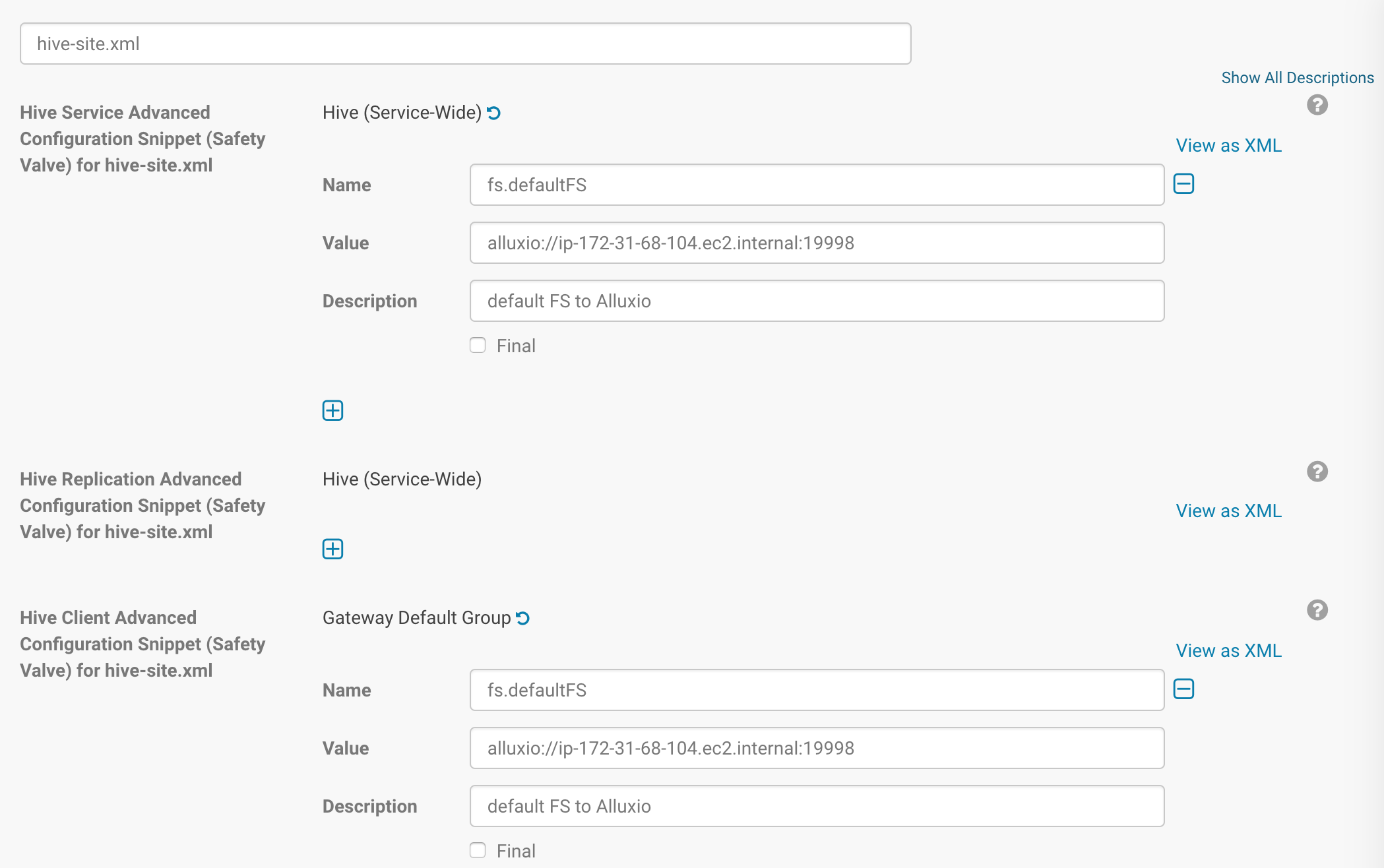
When using Alluxio as the defaultFS, Hive’s warehouse will point to alluxio://master:19999/user/hive/warehouse. This
directory should be created and given permissions hive:hive. This also allows users to define internal tables on
Alluxio.
(Optional) Add additional Alluxio Properties for Hive
If there are any Alluxio site properties you want to specify for Hive, add those to hive-site.xml
similar to how fs.defaultFS was set above. Please ensure Alluxio additional site properties are added
on both Hive Service and Hive Client hive-site.xml. Optionally, you might also want to check whether
it is required to add to Hive Metastore Server and HiveServer2 for hive-site.xml.
Then save the configuration, and the Cloudera Manager will notify you that you should deploy the configuration and restart the affected components. Please restart the affected components.
Running Sample Hive Application
You can follow the sample Hive application on Running-Hive-on-Alluxio.
Running CDH Spark
To run CDH Spark applications with Alluxio, additional configuration is required for the applications.
There are two scenarios for the Spark and Alluxio deployment. If you already have the Alluxio Spark client jars on all the nodes on the cluster, you only have to specify the correct path to for the classpath. Otherwise, you can allow Spark to distribute the Alluxio Spark client jar to each Spark node for each invocation of the application.
Alluxio Spark Client Jar Already on Each Node
If the Alluxio client jar is already on every node, you have to add that path to the classpath for
the Spark driver and executors. In order to do that, use the spark.driver.extraClassPath or --driver-java-options
and the spark.executor.extraClassPath variables.
Note:
spark.executor.extraClassPathandspark.driver.extraClassPathwill overwrite if set more than once. If an application already sets this parameter, the Alluxio client jar needs to be appended to the location where this property is set.
For spark-submit an example looks like the following. (In the example, replace MASTER_HOSTNAME with the
actual Alluxio master hostname.)
$ spark-submit --master yarn --conf "spark.driver.extraClassPath=/path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar" --conf "spark.executor.extraClassPath=/path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar" --class org.apache.spark.examples.JavaWordCount /opt/cloudera/parcels/CDH/lib/spark/examples-1.6.0-cdh5.14.4-hadoop2.6.0-cdh5.14.4.jar alluxio://MASTER_HOSTNAME:19998/testing/randomtext/
Note: This example will run a word count on all text files under Alluxio path
/testing/randomtext/.
And similarly, for spark-shell, the following is an example:
$ spark-shell --master yarn --driver-class-path "/path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar" --conf "spark.executor.extraClassPath=/path/to/alluxio/client/alluxio-enterprise-2.9.0-2.1-client.jar"
Distribute Alluxio Spark Client Jar for Each Application
If the Alluxio client jar is not already on each machine, you can use the --jars option
to distribute the jar for each application.
For example, using spark-submit would look like:
$ spark-submit --master yarn --jars /path/to/alluxio/spark/alluxio-enterprise-2.9.0-2.1-client.jar --class org.apache.spark.examples.JavaWordCount /opt/cloudera/parcels/CDH/lib/spark/examples-1.6.0-cdh5.14.4-hadoop2.6.0-cdh5.14.4.jar alluxio://MASTER_HOSTNAME:19998/testing/randomtext/