

Burst Compute to a Public Cloud
![]()

This guide provides an overview of how to migrate compute workloads from on-premises to the cloud. It describes the migration of compute workloads to a public cloud, accessing data stored on-premises without manual copies or synchronization with cloud storage.
This hybrid cloud model with compute jobs, like Spark or Presto, utilizing compute resources in the public cloud and accessing data stored on-premises, is an appealing solution to reduce resource contention on-premises. One key flaw is the overhead associated with transferring data between the two environments. Data and metadata locality for compute applications must be achieved in order to maintain the performance of analytics jobs as if the entire workload was running on-premises.
We describe a reference architecture with compute applications in a public cloud accessing HDFS on-premises with Alluxio as the data access layer. This document is useful if you’re planning a migration from an on-premises environment to a public cloud.
- Overview
- Benefits from Migrating Compute to the Cloud
- Planning for Compute Migration
- Hybrid Cloud Architecture with Alluxio
- Network Considerations for Remote Data
- Provisioning Plan
- Security
- What’s Next
Overview
When you want to move your Spark or Presto workloads from on-premises to a public cloud, you have managed Hadoop options for compute clusters:
If any of these managed Hadoop environments doesn’t fit your needs, consider running Alluxio on Kubernetes in your public cloud provider of choice.
Standalone deployments of Alluxio with analytics and AI follow the same general principles.
Benefits from Migrating Compute to the Cloud
- Independent scaling and on-demand provisioning of both compute and storage
- Flexibility to use multiple compute engines (the right tool for the job)
- Reduced load on existing infrastructure by moving ephemeral workloads to elastic compute
In spite of the agility offered by a public cloud, the alternative of managing data across the on-premises environment and a public cloud can be daunting. As the architecture moves to a disaggregated compute and storage stack, a data orchestration technology can accelerate the implementation a hybrid cloud strategy.
Planning for Compute Migration
Alluxio integrates with a privately hosted on-premises environment and the public cloud computing environment to provide an enterprise hybrid cloud analytics strategy. Workloads can be migrated to the public cloud on-demand without manually moving data into the cloud. By bringing data to applications on-demand, the performance with Alluxio for migrated workloads is the same as having data co-located in the public cloud. The on-premises environment is offloaded and the I/O overhead is minimized. The execution plan outlined does not require any significant reconfiguration of the on-premise infrastructure, avoids the need to identify and migrate datasets to cloud storage, and hence accelerates the migration process.
- Link Networks. Identify a public cloud provider and establish a link and DNS resolution across the public cloud and the corporate network. The network bandwidth requirement is significantly reduced with Alluxio.
- Finalize Data Platform Configuration. Determine a provisioning plan and analyze projected cost-usage with the chosen instance types and scaling policy.
- Launch the Analytics Cluster. Once the cluster specifications and desired computational frameworks have been identified, launch the cluster on the public cloud. Data can be accessed in an ad-hoc manner without first planning for a tedious migration process.
- Load pre-identified datasets (if any). Warm up the Alluxio cache by
pre-loading any frequently
accessed data sets identified or configure a
policy for migration of
data on-premises to the cloud.
Note: Identification of such datasets is not strictly required but acts as a performance optimization. If not, Alluxio will retrieve any data sets accessed on-demand during the workload.
Hybrid Cloud Architecture with Alluxio
The deployment architecture consists of a cloud compute cluster, with Alluxio co-located with compute, connecting to an HDFS storage cluster on-premises. The core building blocks of this architecture apply to other hybrid cloud environments as well, especially when two clusters are connected by a high latency low bandwidth network interconnection.
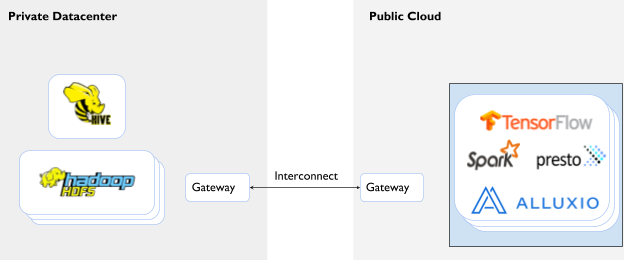
The salient characteristics of the recommended architecture are:
- Co-locate Alluxio close to the compute cluster. Co-location within the same datacenter or cluster ensures the computation framework and data orchestration layer are scaled together, manually or using auto-scaling policies, without additional overhead while ensuring the performance benefits from data locality.
- Mount the on-prem data source. On-premises data stores, like HDFS, are mounted to the Alluxio namespace, enabling on-demand access in the public cloud without copying the data over. Alluxio asynchronously fetches the metadata from HDFS to make data available instantly.
- On-prem storage as the source-of-truth. The storage system on-premises continues to be the persistent data source. All updates from the public cloud are propagated back to the source on-premises, either synchronously or asynchronously.
- No-replication of the Hive Metastore. A query engine, like Presto or Spark SQL, in the public cloud can connect to an existing Hive catalog on-premises without the need to re-define tables or maintain a replicated instance of Hive’s metadata. This is enabled by the feature Transparent URI.
The following aspects are realized with this approach:
- Data locality. Since Alluxio is co-located with compute resource, read / write intensive workloads get a performance boost from node locality and short-circuit access. Similarly, write workloads can proceed without a bandwidth limitation.
- Ease of deployment. Alluxio is deployed and pre-configured natively for Hadoop, Presto, and Spark on managed Hadoop services.
- Ease of manageability. The Alluxio deployment scales up or down elastically without losing data. Even when the Alluxio workers are scaled down to zero instances and then scaled back up, Alluxio can retrieve data from the data source on-premises without interruption.
- Zero Time-to-Available-Data with Long-Running Masters. By having long-running master nodes, Alluxio maintains an up-to-date copy of metadata in sync with the data source even while files are mutated on-premises by prevailing data ingestion pipelines. For example, with HDFS the feature Active Sync is utilized.
Network Considerations for Remote Data
Alluxio can be used to pull remote data from private data centers or remote regions into the cluster. Here are some recommendations and best practices to consider when connecting to remote data on-premises.
Provisioning Plan
The cluster nodes Alluxio is deployed on may be long-running or ephemeral, and can be launched as On-Demand or reclaimable Spot instances based on the application scenario. If Spot instances are reclaimed, Alluxio recovers from the data source on-premises seamlessly.
Alluxio Master(s) store the metadata for the filesystem namespace and are installed on the master node type. The worker node type installs the Alluxio workers, which serves the data after reading it once from the on-premises HDFS. In addition to nodes running the Alluxio master and worker processes, an application scenario may warrant compute-only nodes. These compute-only nodes do not run any Alluxio processes but only run compute tasks.
There are consequences of using ephemeral nodes for different node types running Alluxio processes. For critical workloads, we recommend using persistent nodes.
- Ephemeral Master Nodes. For data sets with a large number of files mounted into Alluxio, a performance lag should be expected immediately after Alluxio master(s) are spawn. Once the master node(s) are spawn, Alluxio asynchronously loads the metadata for mounted storage systems. This load does not block access in parallel; instead metadata is fetched on-demand for the parts of the storage directory tree that are not already loaded.
- Ephemeral Worker Nodes. For worker nodes which are scaled up and down frequently as needed, Alluxio workers may lose cached data if the remaining capacity is not sufficient. Workloads may immediately observe performance degradation after Alluxio workers are spawned and need to access data from the source on-premises. This access is transparent to the applications and no manual intervention is required.
- Ephemeral Compute-Only Nodes. Compute-only nodes can be scaled down as needed without impacting data cached on Alluxio workers. Having dedicated compute-only nodes allows for scaling compute independently of Alluxio worker storage capacity for caching.
Configure the lifecycle of a node based on the node type.
| Scenario | Master Node Lifetime | Worker Node Lifetime |
|---|---|---|
| Long-Running Clusters w/ Predictable Load | Persistent | Persistent |
| Critical Clusters with Bursty Load | Persistent | Ephemeral (with auto-scaling) |
| Non-Critical or Test Clusters | Ephemeral | Ephemeral |
- Long-Running Clusters w/ Predictable Load. If running persistent clusters with predictable capacity requirements, persistent nodes ensure that both Alluxio metadata and previously accessed data remain warm. Workloads run as if data is local for previously accessed data and there is no impact on performance to meet SLAs.
- Critical Clusters with Bursty Load. If the workloads are bursty, persistent master nodes ensure that up-to-date data on-premises is accessible without a lag in the public cloud via Alluxio. Worker nodes, including the Alluxio worker process, may be scaled up or down. For data accessed for the first time, variation in performance could be observed.
- Non-Critical or Test Clusters. For non-critical applications which can tolerate a potential performance variation, ephemeral instances can be used to meet cost requirements.
Security
Alluxio allows you to maintain security mechanisms available on-premises during migration to a hybrid cloud.
- Authentication. Alluxio is typically configured to run in one of the two authentication modes:
SIMPLE
or KERBEROS.
In SIMPLE mode, Alluxio infers the client user from the operating system user.
In KERBEROS mode, authentication is enforced via Kerberos protocol.
There are 2 deployment options for KERBEROS:
- A cluster in a public cloud connects directly to the KDC on-premises.
- A cluster in a public cloud connects to a local KDC, which has been configured with one-way trust to a KDC/Active Directory instance on-premises with cross-realm support.
- Authorization. Alluxio in the public cloud can be used to enforce FileSystem ACLS, as well as policies using a data security framework like Apache Ranger.
- Encryption in motion. Refer to TLS Support.
- Audit Logging. Refer to Audit Logging Support.
What’s Next
- Have a look at our tutorials.