

Use Cases
![]()

![]()
- Use Case 1: Accelerate Analytics and AI in the Cloud
- Use Case 2: Speed-up Analytics and AI for On-premise Object Stores
- Use Case 3: “Zero-Copy” Hybrid Cloud Bursting
- Use Case 4: Hybrid Cloud Storage Gateway for Data in the Cloud
- Use Case 5: Enable Cross Datacenter Access
Many leading companies around the world run Alluxio in production to extract value from their data. Some of them are listed in our Powered-By page. In this section, we will introduce some of the most common Alluxio use cases.
Use Case 1: Accelerate Analytics and AI in the Cloud
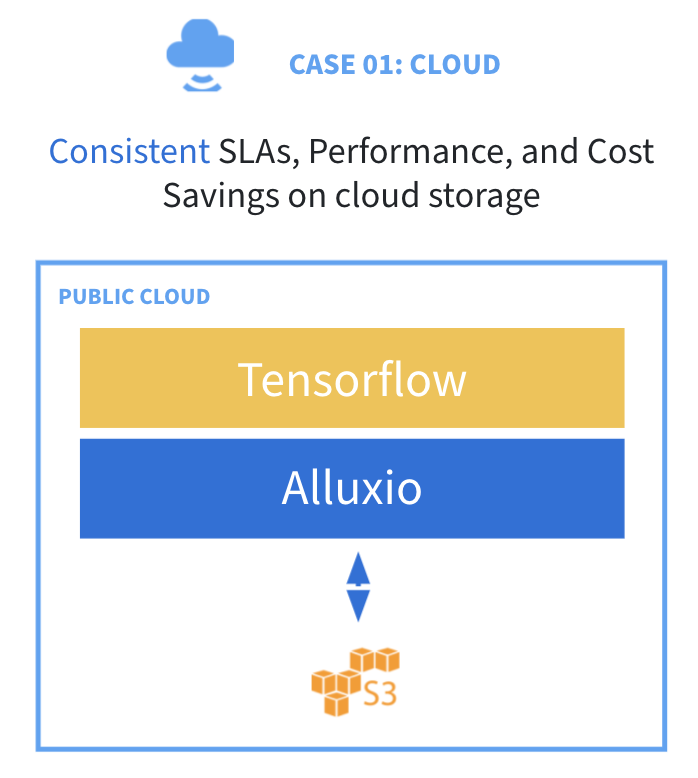
Many organizations are running analytics and machine learning workloads (Spark, Presto, Hive, Tensorflow, etc.) on object storage in the public cloud (AWS S3, Google Cloud, or Microsoft Azure).
Though cloud object stores are often more cost-effective, easier to use, and easier to scale, there are some challenges:
- Performance is variable and consistent SLAs are hard
- Metadata operations are expensive and slowdown workloads
- Embedded caching is ineffective for ephemeral clusters
Alluxio addresses these challenges by providing intelligent multi-tiered caching and metadata management. Deploying Alluxio on the compute cluster helps:
- Achieve consistent performance for analytics engines
- Reduce AI training time and cost
- Eliminate repeated storage access costs
- Achieve off-cluster caching for ephemeral workloads
See this example use case from Electronic Arts.
Use Case 2: Speed-up Analytics and AI for On-premise Object Stores

Running data-driven applications on top of an object store deployed on-premise brings the following challenges:
- Poor performance for analytics and AI workloads
- Lack of enough native support for popular frameworks
- Expensive and slow metadata operations
Alluxio solves these problems by providing caching and API translation. Deploying Alluxio on the application side brings:
- Improved performance for analytics and AI workloads
- Flexibility of segregated storage
- Support for multiple APIs with no changes to the end-user experience
- Reduce the overall storage cost
See this example use case from DBS.
Use Case 3: “Zero-Copy” Hybrid Cloud Bursting
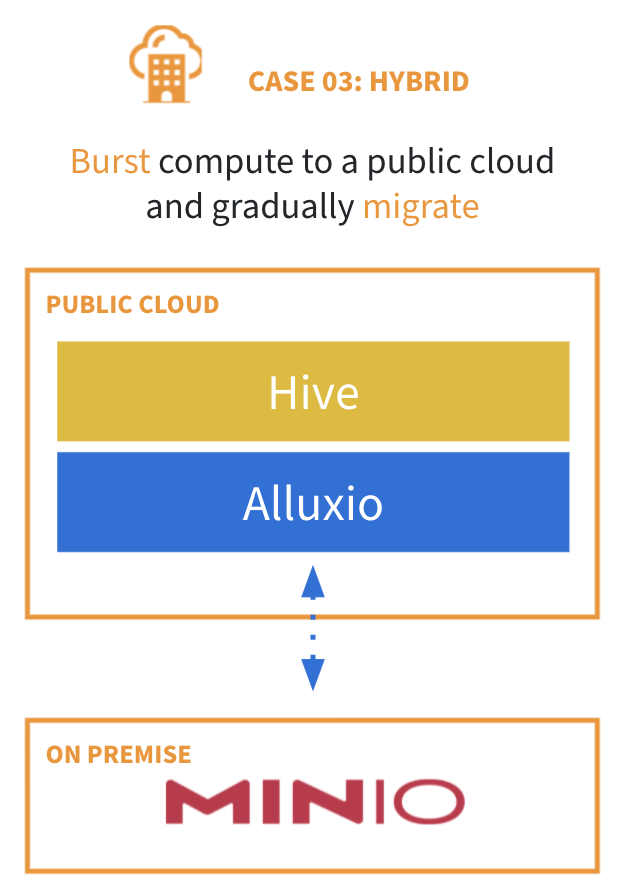
As more organizations are migrating to the cloud, a common intermediate step is to utilize compute resources in the cloud while retrieving data from on-premise data sources. However, this hybrid architecture brings the following problems:
- Data access across the network is slow and inconsistent
- Copying data to cloud storage is time-consuming, error-prone, and complex
- Compliance and data sovereignty requirements may prohibit copying data into the cloud
Alluxio provides “zero-copy” cloud bursting which enables compute engines in the cloud to access data on-premise without the need of a persistent copy of the data in the cloud that needs to be periodically synchronized to the original data on-premises. This brings the following benefits:
- Performance as if data is on the cloud compute cluster
- No changes to end-user experience and security model
- Common data access layer with access-based or policy-based data movement
- Utilization of elastic cloud compute resources and cost savings
See this example use case from Walmart.
Use Case 4: Hybrid Cloud Storage Gateway for Data in the Cloud
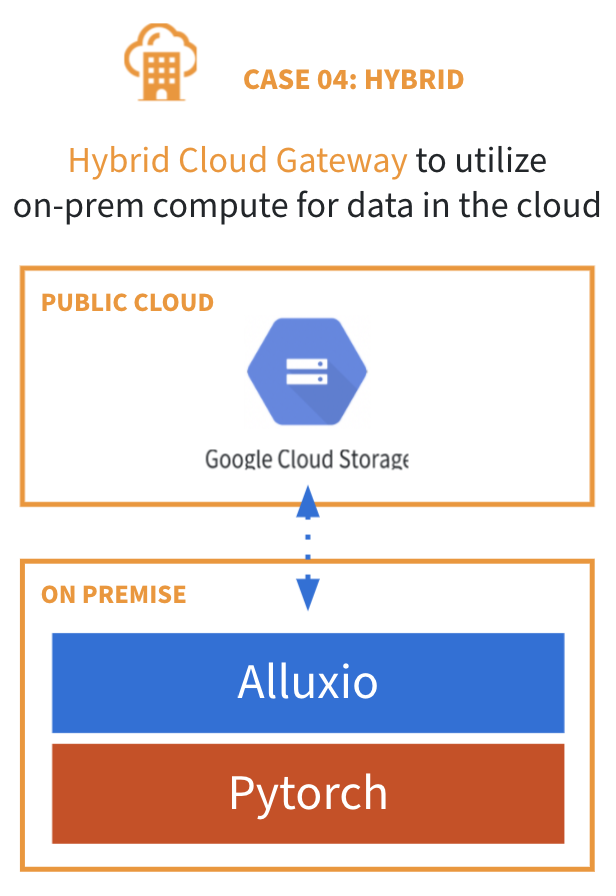
Another hybrid cloud architecture is to access cloud storage from a private datacenter. Using this architecture usually causes the following problems:
- No unified view for cloud and on-premise storage
- Prohibitively high network egress costs
- Inability to utilize compute on-premises for data in the cloud
- Inadequate performance for analytics and AI
Alluxio solves these problems by acting as a hybrid cloud storage gateway that utilizes on-premise compute for data in the cloud. When deployed with the compute on-premise, Alluxio manages the compute cluster’s storage and provides data locality to applications, achieving:
- High performance for reads and writes using intelligent distributed caching
- Network cost savings by eliminating replication
- No changes to the end-user experience with flexible APIs and security model on cloud storage
See this example use case from Comcast.
Use Case 5: Enable Cross Datacenter Access
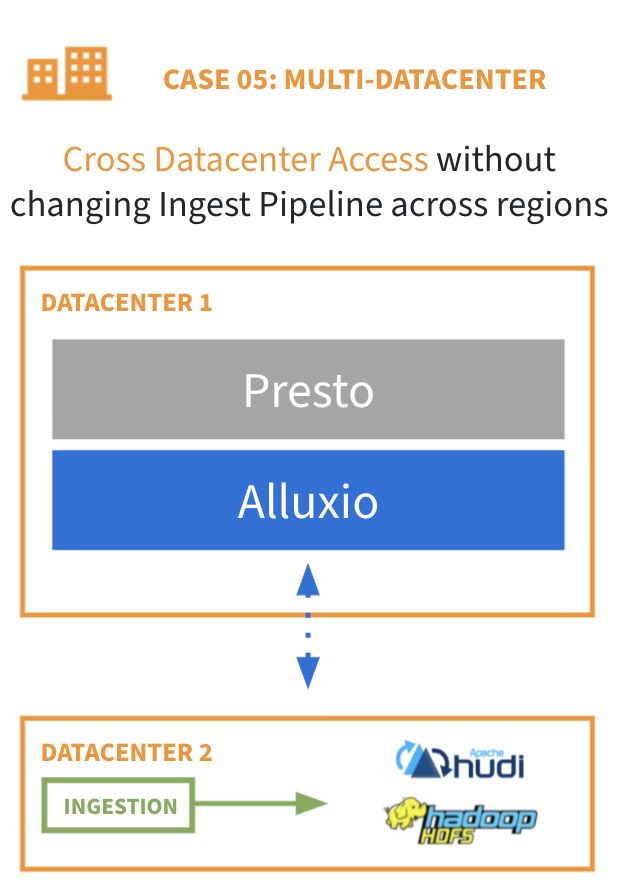
Many organizations maintain satellite compute clusters that are independent of their main data cluster for the purposes of performance, security, or resource isolation. These satellite clusters need to access data remotely from the main cluster, which is challenging because:
- Cross-datacenter copies are manual and time-consuming
- Unnecessary network traffic for replication is expensive
- Replication jobs on an overloaded storage cluster dramatically impact the performance of existing workloads
Alluxio can be deployed on the compute nodes in the satellite cluster and configured to connect to the main data cluster, serving as one logical copy of data. Thus:
- No redundant data copies across datacenters
- Elimination of complex data synchronization
- Improved performance compared to remote region data access
- Self-service data infrastructure across business units