

Running Alluxio on EMR
![]()

![]()
This guide describes how to configure Alluxio to run on AWS EMR.
Overview
AWS EMR provides great options for running clusters on-demand to handle compute workloads. It manages the deployment of various Hadoop Services and allows for hooks into these services for customizations. Alluxio can run on EMR to provide functionality above what EMRFS currently provides. Aside from the added performance benefits of caching, Alluxio enables users to run compute workloads against on-premise storage or a different cloud provider’s storage such as GCS and Azure Blob Store.
Prerequisites
- Account with AWS
- IAM Account with the default EMR Roles
- Key Pair for EC2
- An S3 Bucket
- AWS CLI: configured with your AWS access key id and secret access key
The majority of the pre-requisites can be found by going through the AWS EMR Getting Started guide. An S3 bucket is needed as Alluxio’s root Under File System and to serve as the location for the bootstrap script. If desired, the root UFS can be configured to be HDFS or any other supported under storage. Type of EC2 instance to be used for Alluxio Master and Worker depends on the workload characteristics. General recommended types of EC2 instances for Alluxio Master are r5.4xlarge or r5.8xlarge. EC2 instance types of r5d.4xlarge or r5d.8xlarge enable use of SSD as Alluxio worker storage tier.
Basic Setup
Open a terminal and use the AWS CLI to create the necessary IAM roles on your account.
$ aws emr create-default-roles
The create-cluster command
requires passing in multiple flags to successfully execute:
release-label: The version of EMR to install with. The current version of Alluxio is compatible withemr-5.25.0.instance-count: The number of nodes to provision for the cluster.instance-type: The instance type to provision with. Note that your account is limited in the number of instances you can launch in each region; check your instance limits here. A good instance type to start off with isr4.4xlarge.applications: SpecifyName=Spark Name=Presto Name=Hiveto bootstrap the three additional servicesname: The EMR cluster namebootstrap-actions:Path: The path to the bootstrap script, hosted in a publicly readable S3 bucket:s3://alluxio-public/emr/2.9.1/alluxio-emr.shArgs: The arguments passed to the bootstrap script.- The first argument, the root UFS URI, is required.
This S3 URI designates the root mount of the Alluxio file system and should be of the form
s3://bucket-name/mount-point. The mount point should be a folder; follow these instructions to create a folder in S3. - Specify the path to a publicly accessible Alluxio tarball with the
-dflag. For example, you can use the URL:https://downloads.alluxio.io/downloads/files/2.9.1/alluxio-2.9.1-bin.tar.gz - You can also specify additional Alluxio properties as a delimited list of key-value pairs in the format
key=value. For example,alluxio.user.file.writetype.default=CACHE_THROUGHinstructs Alluxio to write files synchronously to the underlying storage system. See more about write type options.
- The first argument, the root UFS URI, is required.
This S3 URI designates the root mount of the Alluxio file system and should be of the form
configurations: The path to the configuration json file, also hosted in a publicly readable S3 bucket:https://s3.amazonaws.com/alluxio-public/emr/2.9.1/alluxio-emr.jsonAlternatively, download the linked JSON file and provide the local path to the file, ex.file:///path/to/alluxio-emr.json.ec2-attributes: EC2 settings to provide, most notably the name of the key pair used to connect to the cluster.
Below is a sample command with all of the above flags populated:
Note that this command’s formatting is designed for the
bashinterpreter.
$ aws emr create-cluster \
--release-label emr-5.25.0 \
--instance-count 3 \
--instance-type r4.4xlarge \
--applications Name=Spark Name=Presto Name=Hive \
--name try-alluxio \
--bootstrap-actions \
Path=s3://alluxio-public/emr/2.9.1/alluxio-emr.sh,\
Args=[s3://myBucketName/mountPointFolder,\
-d,"https://downloads.alluxio.io/downloads/files/2.9.1/alluxio-2.9.1-bin.tar.gz",\
-p,"alluxio.user.block.size.bytes.default=122M|alluxio.user.file.writetype.default=CACHE_THROUGH",\
-s,"|"] \
--configurations https://alluxio-public.s3.amazonaws.com/emr/2.9.1/alluxio-emr.json \
--ec2-attributes KeyName=myKeyPairName
where s3://myBucketName/mountPointFolder should be replaced with a S3 URI that your AWS account can read and write to
and myKeyPairName should be replaced with the name of your EC2 key pair.
Log into the EMR console.
Once the cluster is in the Waiting stage, click on the cluster details to get the Master public DNS if available
or click on the Hardware tab to see the master and worker details.
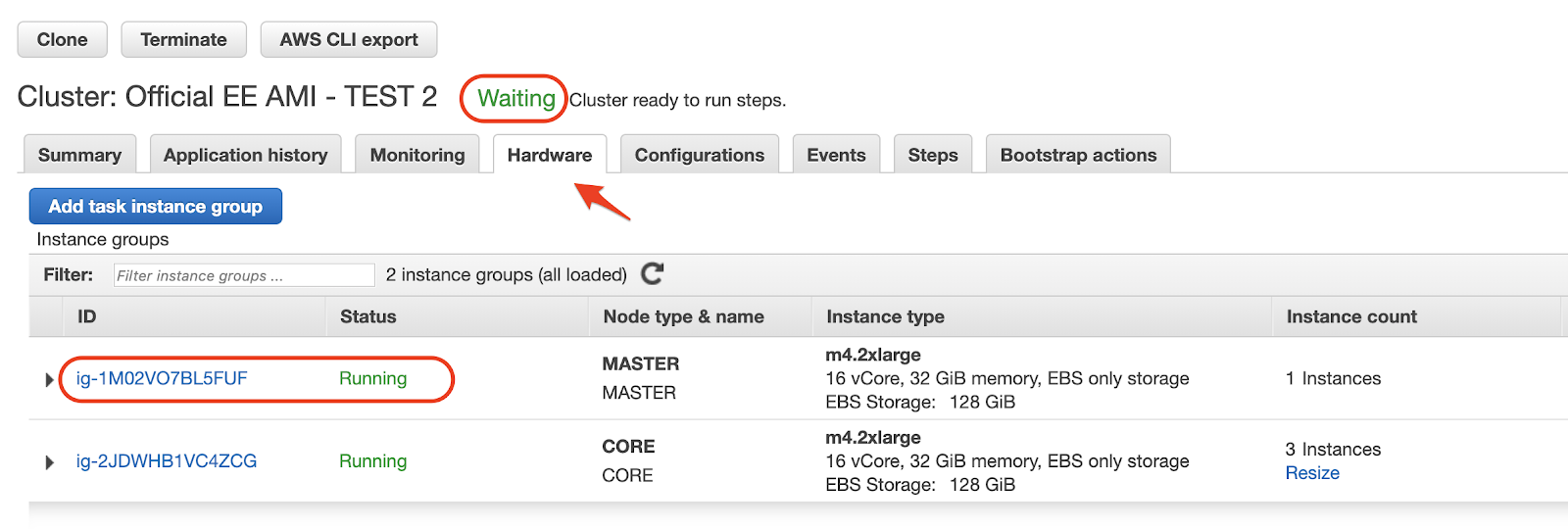
Clicking on the master instance group will show you the public DNS.
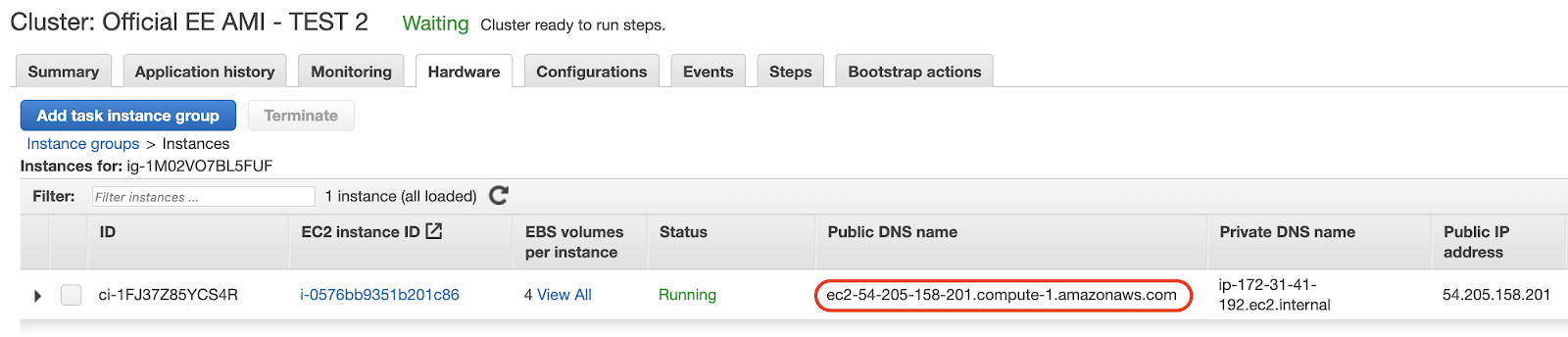
SSH into the master instance using the key pair provided in the previous command.
Use hadoop as the username.
$ ssh -i /path/to/keypair.pem hadoop@<masterPublicDns>
Note that in the example create-cluster command, a security group was not specified,
so a security group is automatically created for the new cluster.
This security group is not configured to allow inbound SSH.
In order for the above SSH command to work, edit the ElasticMapReduce-master
security group in the EC2 console, adding an inbound rule for port 22 with source 0.0.0.0/0.
Read here
for more details.
Once inside the master instance, run the following command to run a series of basic tests to ensure Alluxio can read and write files.
$ sudo runuser -l alluxio -c "/opt/alluxio/bin/alluxio runTests"
Using this bootstrap script, Alluxio is installed in /opt/alluxio/ by default.
Hive and Presto are already configured to connect to Alluxio.
The cluster also uses AWS Glue as the default metastore for both Presto and Hive.
This will allow you to maintain table definitions between multiple runs of the Alluxio cluster.
By default, the Alluxio worker is allocated one third of the instance’s maximum available memory.
Creating a Table
The simplest step to using EMR with Alluxio is to create a table on Alluxio and query it using Presto/Hive.
From your terminal, SSH into the master instance using the key pair provided in the create-cluster
command.
$ ssh -i /path/to/keypair.pem hadoop@<masterPublicDns>
Note that we are connecting as the hadoop user.
All subsequent commands assume they are being executed from within the instance.
Create the /testTable directory in Alluxio, then set the hadoop user to be the directory owner.
Note that these commands are being executed as the alluxio user.
$ sudo runuser -l alluxio -c "/opt/alluxio/bin/alluxio fs mkdir /testTable"
$ sudo runuser -l alluxio -c "/opt/alluxio/bin/alluxio fs chown hadoop:hadoop /testTable"
Open the Hive CLI.
$ hive
Create a database, then check in the Glue console to see if the database is created.
CREATE DATABASE glue;
Use the newly created database and define a table.
USE glue;
create external table test1 (userid INT,
age INT,
gender CHAR(1),
occupation STRING,
zipcode STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LOCATION 'alluxio:///testTable';
Exit the Hive CLI.
$ exit;
Similar to before, create a /tmp directory in Alluxio.
Then set the directory permissions to 777.
$ sudo runuser -l alluxio -c "/opt/alluxio/bin/alluxio fs mkdir /tmp"
$ sudo runuser -l alluxio -c "/opt/alluxio/bin/alluxio fs chmod 777 /tmp"
Open the Presto CLI, specifying hive as the catalog.
$ presto-cli --catalog hive
Use the created database and insert some values into the table.
USE glue;
INSERT INTO test1 VALUES (1, 24, 'F', 'Developer', '12345');
Read back all values in the table with a SELECT statement.
SELECT * FROM test1;
Customization
Tuning of Alluxio properties can be done in a few different locations. Depending on which service needs tuning, EMR offers different ways of modifying the service settings/environment variables.
The following describes all the possible flags that can be passed into the bootstrap script.
In the above example, we used the -p and -s flags to specify additional Alluxio properties
and the delimiting string between properties.
Usage: alluxio-emr.sh <root-ufs-uri>
[-b <backup_uri>]
[-c]
[-d <alluxio_download_uri>]
[-f <file_uri>]
[-i <journal_backup_uri>]
[-l <sync_list>]
[-n <storage percentage>]
[-p <delimited_properties>]
[-s <delimiter>]
[-v <hdfs_version>]
alluxio-emr.sh is a script which can be used to bootstrap an AWS EMR cluster
with Alluxio. It can download and install Alluxio as well as add properties
specified as arguments to the script.
By default, if the environment this script executes in does not already contain
an Alluxio install at ${ALLUXIO_HOME} then it will download, untar, and configure
the environment at ${ALLUXIO_HOME}. If an install already exists at ${ALLUXIO_HOME},
nothing will be installed over it, even if -d is specified.
If a different Alluxio version is desired, see the -d option.
<root-ufs-uri> (Required) The URI of the root UFS in the Alluxio namespace.
If this is the string "LOCAL", the EMR HDFS root will be used
as the root UFS.
-b An s3:// URI that the Alluxio master will write a backup
to upon shutdown of the EMR cluster. The backup and and
upload MUST be run within 60 seconds. If the backup cannot
finish within 60 seconds, then an incomplete journal may
be uploaded. This option is not recommended for production
or mission critical use cases where the backup is relied
upon to restore cluster state after a previous shutdown.
-c Install the alluxio client jars only.
-d An s3:// or http(s):// URI which points to an Alluxio
tarball. This script will download and untar the
Alluxio tarball and install Alluxio at ${ALLUXIO_HOME} if an
Alluxio installation doesn't already exist at that location.
-f An s3:// or http(s):// URI to any remote file. This property
can be specified multiple times. Any file specified through
this property will be downloaded and stored with the same
name to ${ALLUXIO_HOME}/conf/
-i An s3:// or http(s):// URI which represents the URI of a
previous Alluxio journal backup. If supplied, the backup
will be downloaded, and upon Alluxio startup, the Alluxio
master will read and restore the backup.
-l A string containing a delimited list of Alluxio paths.
Active sync will be enabled for the given paths. UFS
metadata will be periodically synced with the Alluxio
namespace. The delimiter by default is a semicolon ";". If a
different delimiter is desired use the [-s] argument.
-n Automatically configure NVMe storage for Alluxio workers at
tier 0 instead of MEM. When present, the script will attempt
to locate mounted NVMe storage locations and configure them
to be used with Alluxio. The argument provided is an
integer between 1 and 100 that represents the percentage of
each disk that will be allocated to Alluxio.
-p A string containing a delimited set of properties which
should be added to the
${ALLUXIO_HOME}/conf/alluxio-site.properties file. The
delimiter by default is a semicolon ";". If a different
delimiter is desired use the [-s] argument.
-s A string containing a single character representing what
delimiter should be used to split the Alluxio properties
provided in the [-p] argument and the sync list provided
in the [-l] argument.
-v Version of HDFS used as the root UFS. Required when
root UFS is HDFS.
Making configuration changes to the Alluxio service can be done in a few different ways via the
bootstrap script.
The -p flag allows users to pass in a set of delimited key-value properties to be set on all of
the Alluxio nodes.
An alternative would be to pass in a custom file using the -f flag named
alluxio-site.properties.
The bootstrap will make sure to overwrite any user-provided configs while retaining any defaults
that are not overwritten.
The bootstrap also allows users to install previous versions of Alluxio (>=2.0) by specifying
a download URL (HTTP or S3 only).
Generic client-side properties can also be edited via the bootstrap script as mentioned above.
This is mostly for the native client (CLI).
Property changes for a specific service like Presto/Hive should be done in the respective section
of the EMR JSON configuration file i.e. core-site.xml or hive.catalog.