
Data Caching
![]()

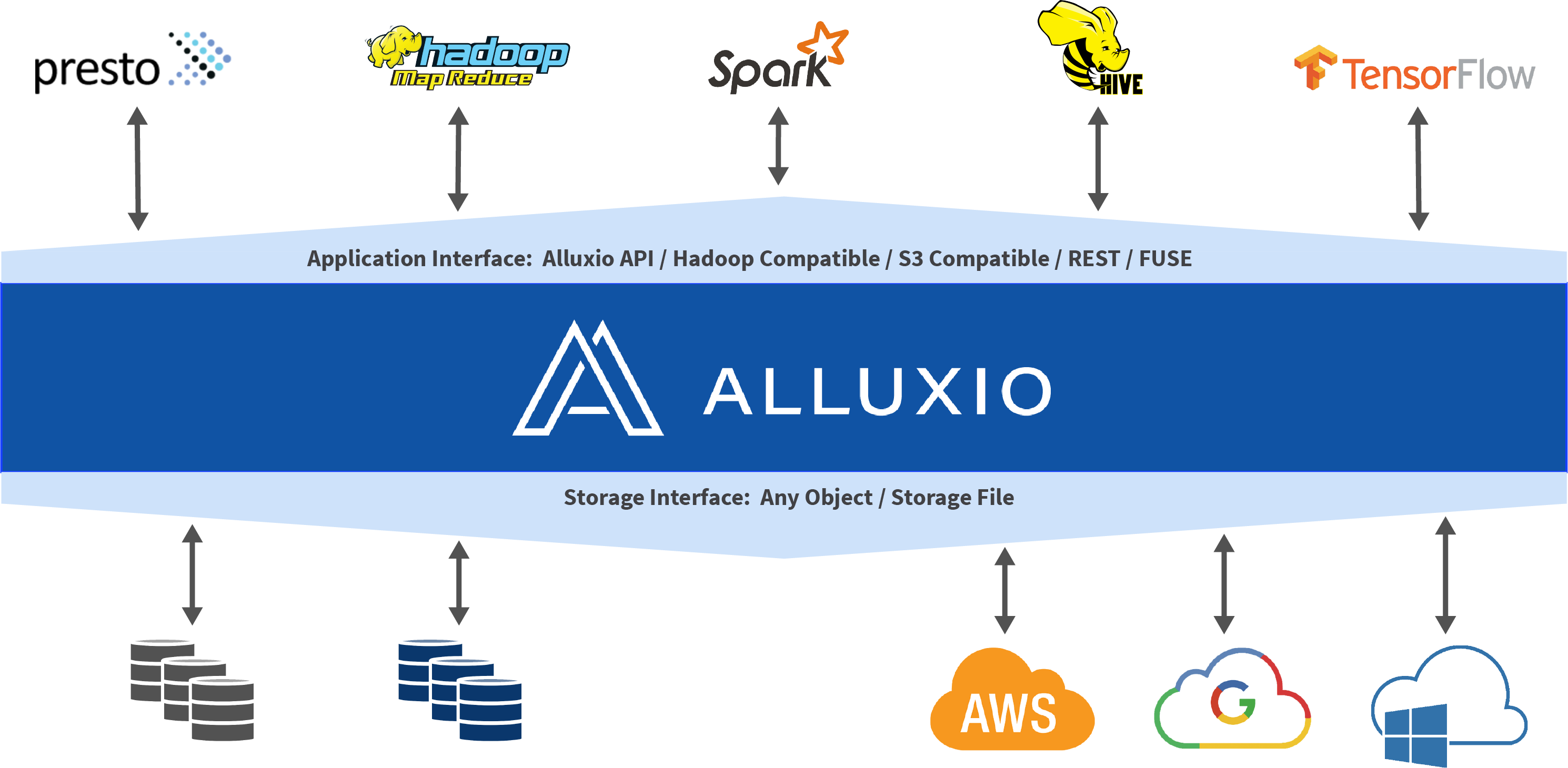
Alluxio Storage Overview
The purpose of this documentation is to introduce users to the concepts behind Alluxio storage and the operations that can be performed within Alluxio storage space.
Alluxio helps unify users’ data across a variety of platforms while also helping to increase overall I/O throughput. Alluxio accomplishes this by splitting storage into two distinct categories.
- UFS (Under File Storage, also referred to as under storage)
- This type of storage is represented as space which is not managed by Alluxio. UFS storage may come from an external file system, including HDFS or S3. Alluxio may connect to one or more of these UFSs and expose them within a single namespace.
- Typically, UFS storage is aimed at storing large amounts of data persistently for extended periods of time.
- Alluxio storage
- Alluxio manages the local storage, including memory, of Alluxio workers to act as a distributed buffer cache. This fast data layer between user applications and the various under storages results in vastly improved I/O performance.
- Alluxio storage is mainly aimed at storing hot, transient data and is not focused on long term persistence.
- The amount and type of storage for each Alluxio worker node to manage is determined by user configuration.
- Even if data is not currently within Alluxio storage, files within a connected UFS are still visible to Alluxio clients. The data is copied into Alluxio storage when a client attempts to read a file that is only available from a UFS.
Alluxio storage improves performance by storing data in memory co-located with compute nodes. Data in Alluxio storage can be replicated to make “hot” data more readily available for I/O operations to consume in parallel.
Replicas of data within Alluxio are independent of the replicas that may exist within a UFS. The number of data replicas within Alluxio storage is determined dynamically by cluster activity. Due to the fact that Alluxio relies on the under file storage for a majority of data storage, Alluxio does not need to keep copies of data that are not being used.
Alluxio also supports tiered storage configurations such as memory, SSD, and HDD tiers which can make the storage system media aware. This enables decreased fetching latencies similar to how L1/L2 CPU caches operate.
Dora Cache Overview
The major shift in the landscape of Alluxio’s metadata and cache management in Project Dora is that there is no longer a single master node in charge of all the file system metadata and cache information. Instead, the “workers”, or simply “Dora cache nodes,” now handle both the metadata and the data of the files. Clients simply send requests to Dora cache nodes, and each Dora cache node will serve both the metadata and the data of the requested files. Since you can have a large number of Dora cache nodes in service, client traffic does not have to go to the single master node, but rather is distributed among the Dora cache nodes, therefore, greatly reducing the burden of the master node.
Load balancing between Dora nodes
Without a single master node dictating clients which workers to go to fetch the data, clients need an alternative way to select its destination. Dora employs a simple yet effective algorithm called consistent hashing to deterministically compute a target node. Consistent hashing ensures that given a list of all available Dora cache nodes, for a particular requested file, any client will independently choose the same node to request the file from. If the hash algorithm used is uniform over the nodes, then the requests will be uniformly distributed among the nodes (modulo the distribution of the requests).
Consistent hashing allows the Dora cluster to scale linearly with the size of the dataset, as all the metadata and data are partitioned onto multiple nodes, without any of them being the single point of failure.
Fault tolerance and client-side UFS fallback
A Dora cache node can sometimes run into serious trouble and stop serving requests. To make sure the clients’ requests get served normally even if a node is faulty, there’s a fallback mechanism supporting clients falling back from the faulty node to another one, and eventually if all possible options are exhausted, falling back to the UFS.
For a given file, the target node chosen by the consistent hashing algorithm is the primary node for handling the requests regarding this file. Consistent hashing allows a client to compute a secondary node following the primary node’s failure, and redirects the requests to it. Like the primary node, the secondary node computed by different clients independently is exactly the same, ensuring that the fallback will happen to the same node. This fallback process can happen a few more times (configurable by the user), until the cost of retrying multiple nodes becomes unacceptable, when the client can fall back to the UFS directly.
Metadata management
Dora cache nodes cache the metadata of the files they are in charge of. The metadata is fetched from the UFS directly the first time when a file is requested by a client, and cached by the Dora node. It is then used to respond to metadata requests afterwards.
Currently, the Dora architecture is geared towards immutable and read-only use cases only. This assumes the metadata of the files in the UFS do not change over time, so that the cached metadata do not have to be invalidated. In the future, we’d like to explore certain use cases where invalidation of metadata is needed but is relatively rare.
Configuring Alluxio Storage
Paging Worker Storage
- ▶️ What is Paging Storage? (1:06)
- ▶️ Benefits of Paging Storage (2:44)
- ▶️ Efficient Alluxio Caching with Paging Storage (1:18)
Alluxio supports finer-grained page-level (typically, 1 MB) caching storage on Alluxio workers, as an alternative option to the existing block-based (defaults to 64 MB) tiered caching storage. This paging storage supports general workloads including reading and writing, with customizable cache eviction policies similar to block annotation policies in tiered block store.
To switch to the paging storage:
alluxio.worker.block.store.type=PAGE
You can specify multiple directories to be used as cache storage for the paging store.
For example, to use two SSDs (mounted at /mnt/ssd1 and /mnt/ssd2):
alluxio.worker.page.store.dirs=/mnt/ssd1,/mnt/ssd2
You can set a limit to the maximum amount of storage for cache for each of the directories. For example, to allocate 100 GB of space on each SSD:
alluxio.worker.page.store.sizes=100GB,100GB
Note that the ordering of the sizes must match the ordering of the dirs. It is highly recommended to allocate all directories to be the same size, since the allocator will distribute data evenly.
To specify the page size:
alluxio.worker.page.store.page.size=1MB
A larger page size might improve sequential read performance, but it may take up more cache space. We recommend to use the default value (1MB) for Presto workload (reading Parquet or Orc files).
To enable the asynchronous writes for paging store:
alluxio.worker.page.store.async.write.enabled=true
You might find this property helpful if you notice performance degradation when there are a lot of cache misses.