

Deploy Alluxio on Kubernetes with Operator
![]()

Alluxio can be run on Kubernetes. This guide demonstrates how to run Alluxio on Kubernetes using the Alluxio Operator.
- Table of Contents
Prerequisites
- A Kubernetes cluster (version 1.20+). You can check the version with
kubectl version. - Ensure the cluster’s Kubernetes Network Policy allows for connectivity between applications (Alluxio clients) and the Alluxio Pods on the defined ports.
Getting Started
You’ll need a Kubernetes cluster to run against. You can use KIND to get a local cluster for testing, or run against a remote cluster.
Note: Your controller will automatically use the current context in your kubeconfig file (i.e. whatever cluster kubectl cluster-info shows).
Once you are ready, you can follow the steps to set up your Alluxio cluster with the Alluxio Operator.
Get the Alluxio Operator package
Contact with our Support Engineer/Sales to get the tarball alluxio-operator.tar.gz and decompress it:
tar -zxvf alluxio-operator.tar.gz && cd alluxio-operator
Build Docker Image for Alluxio Operator
Build and push the image to the location specified by IMG:
make docker-build docker-push IMG=<some-registry>/alluxio-operator:tag
For example:
make docker-build docker-push IMG=alluxio/alluxio-operator:2.9.0
Deploy Alluxio Operator
Deploy the controller to the cluster with the image specified by IMG:
make deploy IMG=<some-registry>/alluxio-operator:tag
By default, the controller’s POD uses the storage on the node where it is located. If you want to deploy the controller with PVC, use the following command instead.
make deploy-pvc IMG=<some-registry>/alluxio-operator:tag
NOTE: deploying with PVC is recommended, but this requires that there is at least one PV resource in your Kubernetes Cluster.
Create a Alluxio Cluster
Install instances of custom resources:
kubectl apply -f config/samples/_v1alpha1_alluxiocluster.yaml
Verify Alluxio is running
Get the external IP of the master node
kubectl get services -n alluxio-system
The above command will output something similar to the following:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alluxio-master-external-service ClusterIP 10.105.41.66 172.17.195.75 19998/TCP,19999/TCP,20001/TCP,20002/TCP,19200/TCP,20003/TCP,30075/TCP 51s
alluxio-master-headless-service ClusterIP None <none> 19998/TCP,19999/TCP,20001/TCP,20002/TCP,19200/TCP,20003/TCP,30075/TCP 72s
alluxio-controller-manager-metrics-service ClusterIP 10.107.185.173 <none> 8443/TCP 6d20h
Visit the master Web UI with the browser. In this example, the URI of the master WEB UI should be http://172.17.195.75:19999.
Destroy the Created Alluxio Cluster
To destroy the created alluxio cluster, we just need to delete the custom resource. We can execute the following command to see if there is any installed custom resource.
kubectl get AlluxioCluster -A
Then the return should be as follows:
NAMESPACE NAME AGE
alluxio-system alluxio 29h
Taking the above example, the cluster can be destroyed using the following command:
kubectl delete AlluxioCluster alluxio -n alluxio-system
Common Operations
Install CRD
To install the CRD to the Kubernetes cluster without deploying the Alluxio Operator on a POD:
make install
Uninstall CRD
To delete the CRD from the cluster:
make uninstall
Undeploy controller
To undeploy the controller in the cluster:
make undeploy
Architecture
The Alluxio Operator is based on the operator sdk. It acts as other controllers of the Kubernetes resources (e.g. DaemonSet, StatefulSet and Deployment), and runs as a process on a Pod. It detects and maintains the status of AlluxioCluster resource which is a CR (custom resource) for better managing Alluxio cluster.
The Alluxio Operator also provide a CRD (custom resource definition) to draw what does a CR yaml file of the AlluxioCluster resource looks like.
Without the Alluxio Operator, if we want to create an Alluxio cluster in the Kubernetes environment, we have to create all the Kubernetes resources such as DaemonSet, StatefulSet, Deployment and Service by ourselves to set up the Alluxio cluster. Now having the Alluxio Operator, we are able to create an Alluxio cluster conveniently by submitting the CR to the Kubernetes cluster. It is much easier to configure only one CR yaml file. We can also adjust the configuration items in the CR yaml file as needed. For more details, we will talk about the CR in the following section.
Once the submitted CR is detected by the Alluxio Operator, it helps us create a specific Alluxio cluster according to the configuration described in the CR. Specifically, all the necessary resources will be created automatically.
Overview of the Resources
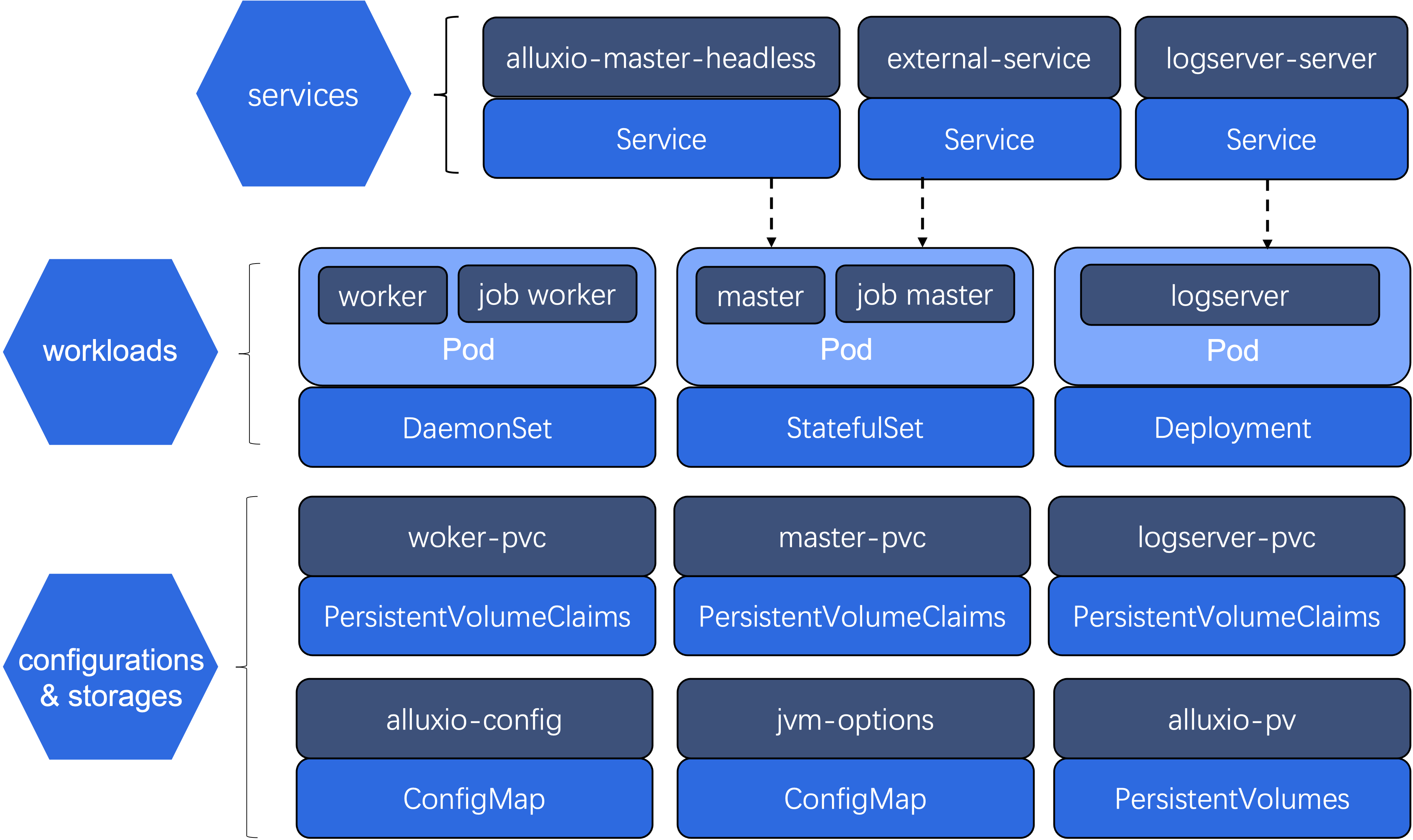
Given a CR, the Alluxio Operator will create the following resources (see Figure 1):
- ConfigMap. It is used for storing all the configurations required by alluxio components, including master, job master, worker, job worker and logserver. Other resources depend on the ConfigMap resources.
- PersistentVolumeClaim. It provides basic storage for Deployment, StatefulSet and DaemonSet. This further enables high available for logserver, master and worker.
- Deployment. It is for the Alluxio logserver. logserver will be deployed on a Pod which is managed by the Deployment.
- StatefulSet. It is for the Alluxio master. As journal is run on master, we need StatefulSet to manage master’s state. master and job master will run on the same Pod which is managed by the StatefulSet.
- DaemonSet. It is for the Alluxio worker. As we expect that there is only one worker on the node, we use DaemonSet to satisfy this requirement. Similar with master and job master, worker and job worker will run on the same Pod which is managed by the DaemonSet.
- Service. It is used for providing network connectivity across client, logserver, master and worker. It also exposes the ports allowing user to access the Alluxio Web UI.
Custom Resource
The Alluxio configurations are described in the CR yaml file. A sample CR yaml file can be seen under config/samples/ directory.
This yaml file can be mainly split into four parts.
Alluxio Configuration
Alluxio configurations can be set in the CR. In the following sample, we specify the root UFS, hostnames and ports of master, job master, worker and job worker. Meanwhile, we set the tiered storage for worker.
jvmOpts:
ALLUXIO_JAVA_OPTS: |-
-Dalluxio.master.mount.table.root.ufs=s3://underFSStorage/ -Daws.accessKeyId=XXXXXXXXXXXXXXXXXXXX -Daws.secretKey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ALLUXIO_MASTER_JAVA_OPTS: |-
-Dalluxio.master.hostname=${ALLUXIO_MASTER_HOSTNAME}
ALLUXIO_JOB_MASTER_JAVA_OPTS: |-
-Dalluxio.master.hostname=${ALLUXIO_MASTER_HOSTNAME}
ALLUXIO_WORKER_JAVA_OPTS: |-
-Dalluxio.worker.hostname=${ALLUXIO_WORKER_HOSTNAME} -Dalluxio.worker.rpc.port=29999 -Dalluxio.worker.web.port=30000 -Dalluxio.worker.container.hostname=${ALLUXIO_WORKER_CONTAINER_HOSTNAME} -Dalluxio.worker.ramdisk.size=2G -Dalluxio.worker.tieredstore.levels=2 -Dalluxio.worker.tieredstore.level0.alias=MEM -Dalluxio.worker.tieredstore.level0.dirs.mediumtype=MEM -Dalluxio.worker.tieredstore.level0.dirs.path=/dev/shm -Dalluxio.worker.tieredstore.level0.dirs.quota=1G -Dalluxio.worker.tieredstore.level0.watermark.high.ratio=0.95 -Dalluxio.worker.tieredstore.level0.watermark.low.ratio=0.7 -Dalluxio.worker.tieredstore.level1.alias=HDD -Dalluxio.worker.tieredstore.level1.dirs.mediumtype=HDD -Dalluxio.worker.tieredstore.level1.dirs.path=/mnt/alluxio-nvme0n1 -Dalluxio.worker.tieredstore.level1.dirs.quota=2G -Dalluxio.worker.tieredstore.level1.watermark.high.ratio=0.95 -Dalluxio.worker.tieredstore.level1.watermark.low.ratio=0.7
ALLUXIO_JOB_WORKER_JAVA_OPTS: |-
-Dalluxio.worker.hostname=${ALLUXIO_WORKER_HOSTNAME} -Dalluxio.job.worker.rpc.port=30001 -Dalluxio.job.worker.data.port=30002 -Dalluxio.job.worker.web.port=30003
Additionally, we can create files with content we want by setting configs and secretes attributes in the CR. They can be used by the volumes attribute
in logServerSpec, masterSpec, and workerSpec. In the follow sample, we create the metrics.properties file which enables metrics sinking.
configs:
- name: "metrics.properties"
props:
"sink.prometheus.class": "alluxio.metrics.sink.PrometheusMetricsServlet"
secrets:
- name: "mysecret"
data:
username: "YWRtaW4="
password: "MWYyZDFlMmU2N2Rm"
Log Server Specification
Log server specification enables to create a logserver process on a Pod which is managed by a Deployment resource.
As we can see in the follow sample, logs path is set to /opt/alluxio/logs, storage size is set to 4Gi,
and the port is set to 45600. In this sample, we also use the secret in the volumes.
Finally, we restrict the cpu and memory in logServerCpuMemConf.
If we don’t need the logserver, setting enabled to false allows us to disable it.
logServerSpec:
enabled: true
nodeSelector:
logserver: "true"
port: 45600
hostPath: "/opt/alluxio/logs"
pvcStorage: "4Gi"
logServerCpuMemConf:
cpu.requests: "100m"
cpu.limits: "500m"
mem.requests: "100Mi"
mem.limits: "500Mi"
additionalVolumeConf:
volumes:
- name: secrete-volume
secret:
secretName: mysecret
volumeMounts:
- name: secrete-volume
mountPath: /opt/secret
Master Specification
Master specification allows us to specify the number of alluxio masters. The Alluxio Operator will create a StatefulSet
resource to manage our masters. In the following sample, we set the number of masters to 3, and give a 1Gi storage to
it for journal storage. Similar with logServerConf, we mount the same secret here. In masterCpuMemConf, we restrict the cpu and memory of master and job master.
masterSpec:
replicas: 3
journalSpec:
journalStorageClass: standard
journalStorageSize: 1Gi
nodeSelector:
master: "true"
masterCpuMemConf:
"master.cpu.requests": "100m"
"master.cpu.limits": "1000m"
"master.mem.requests": "100Mi"
"master.mem.limits": "500Mi"
"job.master.cpu.requests": "100m"
"job.master.cpu.limits": "1000m"
"job.master.mem.requests": "100Mi"
"job.master.mem.limits": "500Mi"
additionalVolumeConf:
volumes:
- name: secrete-volume
secret:
secretName: mysecret
volumeMounts:
- name: secrete-volume
mountPath: /opt/secret
Worker Specification
Worker will be deployed based on DaemonSet. Worker specification allows us to specify which nodes to select.
In the following sample, we want nodes that have the label worker=true to be the worker nodes.
Moreover, we declare a 2Gi Persistent Volume Claim for the worker.
Finally, we restrict the cpu and memory of worker and job worker in workerCpuMemConf.
workerSpec:
nodeSelector:
worker: "true"
workerCpuMemConf:
"worker.cpu.requests": "100m"
"worker.cpu.limits": "1000m"
"worker.mem.requests": "100Mi"
"worker.mem.limits": "500Mi"
"job.worker.cpu.requests": "100m"
"job.worker.cpu.limits": "1000m"
"job.worker.mem.requests": "100Mi"
"job.worker.mem.limits": "500Mi"
additionalVolumeConf:
pvcConfigs:
- name: alluxio-nvme0n1
volumeMode: Filesystem
storage: 2Gi
volumes:
- name: hdd
persistentVolumeClaim:
claimName: alluxio-nvme0n1
- name: secrete-volume
secret:
secretName: mysecret
volumeMounts:
- name: hdd
mountPath: /mnt/alluxio-nvme0n1
- name: secrete-volume
mountPath: /opt/secret